Tutti coloro che hanno a che fare con il web, prima o poi, potranno avere a che fare con un servizio di web hosting: non solo chi avvia il sito di una startup o il blog aziendale, ma anche chi decide di cambiarlo perchè non è soddisfatto dal livello di quello attuale. Ognuno, inutile sottolinearlo, vorrebbe che il proprio sito sia veloce ed efficente, possibilmente senza dover spendere un capitale, e naturalmente ciò coincide con quello che la maggioranza dei provider di hosting promette. Trovare un buon servizio di hosting richiede un po’ di sana conoscenza di base della tecnologie e delle sue dinamiche: anche tu potrai farlo!
Quando si sceglie un servizio, dunque, le cose da sapere sono non poche, e le vedremo di seguito.
Tecnologie open source
La scelta più popolare in assoluto (praticamente da sempre) è legata alla “combo” MySQL, PHP, server Apache (o al limite Nginx) e macchine Linux (il cosiddetto stack LAMP); questa scelta viene ormai data per scontata, mentre le ragioni per cui avviene sarebbero da discutere a livello più che altro discorsivo. Non ci interessa quindi capire tanto perchè, ma sapere che il nostro hosting dovrà avere supporto ad una versione stable e recente di PHP, supportare database MySQL ed avere un server Apache. Questi software, infatti, offrono la maggioranza delle soluzioni open source di alto livello, e ciò fa “gola” a webmaster e web developer perchè si tratta, tra l’altro, di tecnologie:
facili da sviluppare, ad esempio sulla base delle indicazioni del codex di WordPress;
non difficili da espandere, sfruttando ad esempio il Composer di PHP;
dotate di numerosi plugin, librerie e CMS open source;
dotate di ampio supporto nella comunità e nei forum liberi: basta “chiedere” a Google, il più delle volte, e troverete la risposta che vi serve.
Del resto il succitato WordPress, una delle soluzioni software più usate per i siti web attuali, si basa su queste tecnologie, con una community di blogger e sviluppatori estremamente attiva e costantemente alla ricerca di bug, miglioramenti e proposte.
Scegliere l’hosting giusto per il tuo sito web passa, quindi, molto spesso per l’open source, peraltro l’unica sostanziale alternativa gratuita ai costosi software commerciali. Sfruttando il modello open source, inoltre, gli sviluppatori web hanno la possibilità di far pagare i propri servizi o consulenze al netto del costo del software, con la sola aggiunta del prezzo del dominio e dell’hosting web. Tieni conto di questo perchè, se scegli una soluzione open source come quelle succitate quando compri hosting e dominio, avrai bisogno di formarti o di farti seguire almeno in parte (e per la manutenzione a lungo periodo) da un esperto del settore.
Le alternative all’open source non mancano ma, per varie ragioni, si sono sviluppate in ambito web solo in ambiti relativamente “ristretti”, spesso soggetti ad accordi di non divulgazione.
Caratteristiche importanti degli hosting
Le principali feature che sono utili da valutare al fine di trovare un hosting di qualità sono le seguenti:
il livello di assistenza da parte dell’hosting, in caso di difficoltà ;
la presenza di un pannello DNS per gestire il dominio e reperire NS, DNS ed auth code;
la possibilità di disporre di banda (per supportare il traffico dei visitatori) e spazio web (per contenere i file del sito) abbastanza capienti e, in alcuni casi, illimitate;
la disponibilità dei servizi cPanel o Plesk per facilitare la gestione di uno o più siti web.
Non esiste una classificazione definitiva delle caratteristiche di un hosting che lo rendano migliore di altri: l’esperienza diretta, le aspettative e le proprie conoscenze tecnologiche possono influire parecchio sulle valutazioni.
Il costo dell’hosting può variare caso per caso, ma nella maggioranza dei casi è proporzionale al rischio che si assume l’impresa nell’operare sul web; ovviamente non tutte le soluzioni sono uguali, e tutto cambia radicalmente in funzione di ciò che l’hosting ci da’ a livello di servizi, utility ed assistenza personalizzata.
Di solito, comunque, gli hosting permettono di effettuare downgrade ed upgrade dei servizi che diventano così, di fatto, scalabili sulle esigenze effettive del momento.
Le soluzioni più diffuse di hosting sono i cloud ed i condivisi, almeno in questi anni.
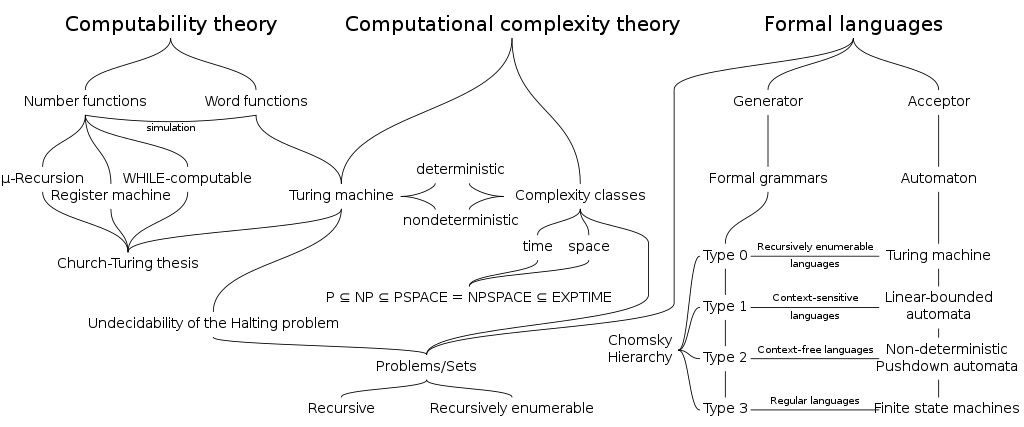
La tesi di Turing-Church è uno dei problemi fondanti dell’informatica per come la conosciamo oggi, e prende ogni presupposto dal trovare una risposta al problema di decisione sollevato da David Hilbert (noto storicamente come entscheidungsproblem, in tedesco, come la lingua parlata dal suo ideatore).
Tale problema si chiede, molto in breve, se si potesse – o meno – stabilire la verità di qualunque enunciato matematico per via di un algoritmo. Il problema di decisione di Hilbert era stato formulato nel 1928 e aveva tenuto banco in ambito accademico per molto tempo.
Nel frattempo (1931) Kurt Gödel aveva dimostrato il teorema di incompletezza, dimostrando che per qualsiasi sistema formale che possa includere l’aritmetica, ci sono proposizioni che sono verità non dimostrabili all’interno di quel sistema. Il teorema di incompletezza ha avuto anch’esso profonde implicazioni per la teoria dei fondamenti della matematica e per la comprensione dei limiti della logica e della dimostrabilità all’interno dei sistemi formali.
Siamo partiti, pertanto, da due aspetti basilari:
è possibile dimostrare qualsiasi enunciato matematico con un software?
esistono sistemi formali a base aritmetica che prevedono proposizioni non dimostrabili.
Uno schema riassuntivo di informatica teorica e dei suoi concetti base. RobinK, Paeng, Mkleine, CC BY-SA 3.0 <http://creativecommons.org/licenses/by-sa/3.0/>, via Wikimedia Commons
Formulazione della tesi di Church-Turing
la Tesi di Church-Turing afferma che se un certo processo può essere descritto in modo algoritmico (ovvero può essere “calcolato” in senso matematico), allora può essere modellato e simulato da una macchina di Turing. Questo è un principio fondamentale nella teoria dell’informatica che collega diverse nozioni di calcolabilità, come i calcolatori, le funzioni matematiche e i concetti di calcolo.
Alonso Church – By Princeton University, Fair use, https://en.wikipedia.org/w/index.php?curid=6082269
La Tesi di Church-Turing non è stata dimostrata, ma è piuttosto un’ipotesi che è stata ampiamente accettata sulla base delle prove empiriche che mostrano la capacità delle macchine di Turing e dei modelli equivalenti di esprimere una vasta gamma di processi algoritmici. La tesina ha contribuito a stabilire l’idea di calcolabilità e ha fornito la base per lo sviluppo della teoria dell’informazione e della computazione. Se un linguaggio di programmazione è in grado di esprimere tutte le funzioni calcolabili (cioè, se può simulare il comportamento di una macchina di Turing universale), allora è possibile affermare che quel linguaggio è “computazionalmente completo”.
Questa applicazione aiuta a stabilire i limiti e le capacità di vari linguaggi di programmazione e consente agli sviluppatori di comprendere quali problemi possono essere risolti utilizzando un determinato linguaggio. Ad esempio, la costruzione di linguaggi di programmazione con caratteristiche avanzate o paradigmi specifici può essere guidata dalla comprensione di come tali linguaggi possono simulare le macchine di Turing o altri modelli equivalenti.
Alan Turing – By Possibly Arthur Reginald Chaffin (1893-1954) – http://www.turingarchive.org/viewer/?id=521&title=4, Public Domain, https://commons.wikimedia.org/w/index.php?curid=22828488
Inoltre, la Tesi di Church-Turing è alla base della teoria dell’automazione e dell’informatica teorica. Essa aiuta a definire ciò che può essere calcolato e a stabilire i limiti delle capacità di calcolo. Pertanto, l’applicazione principale della Tesi di Church-Turing è nell’orientare la progettazione dei linguaggi di programmazione, la comprensione della calcolabilità e la definizione dei concetti fondamentali nella teoria dell’informazione e della computazione.
La tecnologia Node.js introduce delle innovazioni enormi nel campo della tecnologia web, soprattutto perchè riduce la quantità di codice da scrivere e perchè sovverte uno dei dettami delle comunicazioni client-server, ovvero il fatto che Javascript possa eseguirsi solo sui client. Con Node.js, è infatti consentito l’utilizzo server-side del linguaggio in questione, con enormi possibilità sul piano applicativo e pratico.
Di base, Node.js permette di costruire applicazioni basate su un framework asincrono e event-driven, cioè guidato dagli eventi: questo significa che può ad esempio essere aperta una o più connessioni su una porta, e lasciarla in sospeso (cioè senza consumare risorse del server) finchè non avverrà effettivamente la chiamata al servizio – con un click, con una chiamata a funzione o con qualsiasi altro avvenimento, o event, equivalente.
Il vantaggio principale di questo approccio, contrapposto a quello basato su eventi concorrenti o multi-thread (Apache), sta nel fatto che permette di gestire in modo più snello grosse quantità di traffico in arrivo su un sito, un’app o un servizio. In pratica chi ha inventato questa tecnologia aveva in mente di snellire le grosse quantità di richieste che arrivano a grossi picchi periodici, ad esempio, che sono tipicamente difficili da gestire con server classici e che portano a blocchi, errori o rallentamenti di vari ordini e grado.
Tra l’altro, il suo utilizzo non impone l’uso di un singolo processo alla volta: mediante Node.js si possono gestire veri e propri cluster e bilanciare così al meglio le risorse hardware che si hanno a disposizione.
Un esempio pratico
L’esempio classico di Node.js riguarda la facilità con cui si può aprire una connessione HTTP sulla porta 1337, e lasciarla in ascolto per un tempo indeterminato.
A differenza di quanto avviene in PHP, che è un interprete di comando classico (al massimo multi-thread), Node.js permette di sfruttare la compilazione Just-In-Time asincrona basata sugli eventi I/O, con l’ausilio dell’engine V8 di Chrome.
Hosting per Node.js: ancora non troppo diffusi, ma…
Tale innovazione pone – al di là della curva di apprendimento del modello, neanche troppo ripida – un problema di ordine pratico, qualora ci servisse su un servizio di hosting: gli ambienti condivisi ordinari non vanno bene per lo scopo, e quelli più avanzati vanno comunque configurati a dovere. In molti casi le soluzioni di hosting di questo tipo non hanno avuto molto successo e sono sparite dalla circolazione, e soltanto poche (purtroppo) ad oggi sono sopravvissute.
Nonostate tutto, alcuni hosting che danno la possibilità di disporre di Node.js, per la cronaca, sono ad esempio Google Cloud (a pagamento) e Cloudno.de (free).
In Java, i costruttori sono speciali metodi utilizzati per inizializzare nuovi oggetti di una classe. Ogni volta che si crea un’istanza di una classe tramite la parola chiave new, viene chiamato un costruttore che imposta lo stato iniziale dell’oggetto, cioè i valori dei suoi attributi. Un costruttore ha lo stesso nome della classe e non ha un tipo di ritorno, nemmeno void. È possibile definire più costruttori nella stessa classe, differenziandoli per il numero o tipo di parametri, una tecnica nota come overloading del costruttore, che consente di creare oggetti con diversi livelli di dettaglio o configurazioni iniziali. Se non si definisce alcun costruttore, Java fornisce un costruttore di default senza parametri che inizializza gli attributi ai valori predefiniti (es. numeri a 0, booleani a false, oggetti a null).
Gli array di oggetti in Java sono strutture dati che permettono di memorizzare più istanze di una classe in una sequenza ordinata, accessibile tramite un indice numerico a partire da zero. A differenza degli array di tipi primitivi (come int[] o double[]), gli array di oggetti contengono riferimenti agli oggetti, non gli oggetti stessi. Ciò significa che quando si crea un array di oggetti, gli elementi sono inizialmente null fino a quando non vengono istanziati singolarmente con new. Gli array di oggetti sono utili per gestire collezioni omogenee di dati, come una lista di studenti, prodotti o veicoli, e facilitano operazioni come iterazioni, ricerche e ordinamenti su insiemi di oggetti.
Esempio 1: Definizione di una classe con costruttore semplice
public class Studente {
String nome;
int eta;
// Costruttore
public Studente(String nome, int eta) {
this.nome = nome;
this.eta = eta;
}
public void stampaInfo() {
System.out.println("Nome: " + nome + ", Età: " + eta);
}
}
Qui la classe Studente ha un costruttore che inizializza i campi nome ed eta. Ogni volta che si crea un oggetto Studente, bisogna fornire nome ed età.
Esempio 2: Creazione e inizializzazione di un array di oggetti
public class Main {
public static void main(String[] args) {
Studente[] classe = new Studente[3]; // array di 3 studenti
classe[0] = new Studente("Anna", 20);
classe[1] = new Studente("Luca", 22);
classe[2] = new Studente("Marco", 19);
for (Studente s : classe) {
s.stampaInfo();
}
}
}
In questo esempio viene creato un array di riferimento classe lungo 3, quindi ciascuna posizione viene inizializzata con un nuovo oggetto Studente. Il ciclo for-each stampa le informazioni di tutti gli studenti.
Esempio 3: Overloading del costruttore e array di oggetti non completamente inizializzati
public class Prodotto {
String nome;
double prezzo;
// Costruttore con parametri
public Prodotto(String nome, double prezzo) {
this.nome = nome;
this.prezzo = prezzo;
}
// Costruttore di default
public Prodotto() {
this.nome = "Prodotto generico";
this.prezzo = 0.0;
}
public void descrizione() {
System.out.println(nome + ": €" + prezzo);
}
}
public class Negozio {
public static void main(String[] args) {
Prodotto[] scaffale = new Prodotto[5];
scaffale[0] = new Prodotto("Bottiglia", 1.5);
scaffale[1] = new Prodotto("Pane", 0.9);
// gli altri elementi sono null
for (int i = 0; i < scaffale.length; i++) {
if (scaffale[i] != null) {
scaffale[i].descrizione();
} else {
System.out.println("Posizione " + i + " vuota");
}
}
}
}
In questo caso la classe Prodotto ha due costruttori: uno con parametri e uno di default che assegna valori generici. Nell’array scaffale solo alcune posizioni sono inizializzate, mentre le altre rimangono null, quindi è necessario controllare prima di usarle.
Vediamo i singoli pezzi uno per volta, a questo punto.
Costruttore
Un costruttore è un metodo speciale che crea un oggetto e inizializza i suoi valori.
Sintassi base:
public class Persona {
String nome;
int età;
// Costruttore
public Persona(String nome, int età) {
this.nome = nome;
this.età = età;
}
public void saluta() {
System.out.println("Ciao, sono " + nome + " e ho " + età + " anni.");
}
}
this.nome si riferisce alla variabile dell’oggetto, non al parametro
Il costruttore ha lo stesso nome della classe
File: Main.java
public class Main {
public static void main(String[] args) {
Persona p1 = new Persona("Luca", 30);
Persona p2 = new Persona("Giulia", 25);
p1.saluta();
p2.saluta();
}
}
Array di oggetti
Puoi creare un array che contiene più oggetti dello stesso tipo.
Esempio: array di Persona
public class Main {
public static void main(String[] args) {
Persona[] rubrica = new Persona[3]; // array di 3 persone
rubrica[0] = new Persona("Anna", 20);
rubrica[1] = new Persona("Marco", 35);
rubrica[2] = new Persona("Elena", 27);
for (int i = 0; i < rubrica.length; i++) {
rubrica[i].saluta();
}
}
}
File completo per test (2 file)
Persona.java
public class Persona {
String nome;
int età;
public Persona(String nome, int età) {
this.nome = nome;
this.età = età;
}
public void saluta() {
System.out.println("Ciao, mi chiamo " + nome + " e ho " + età + " anni.");
}
}
Main.java
public class Main {
public static void main(String[] args) {
Persona[] persone = {
new Persona("Alice", 22),
new Persona("Giorgio", 28),
new Persona("Chiara", 31)
};
for (Persona p : persone) {
p.saluta();
}
}
}
▶️ Compila e avvia:
javac Persona.java Main.java
java Main
Vuoi aggiungere funzionalità tipo ricerca per nome, input da tastiera, o fare una rubrica vera con menu? Posso guidarti passo passo.
Python, PHP, C++: la miriade di linguaggi informatici a disposizione è sempre più ampia, flessibile e variegata. Se è vero che molto del processo di apprendimento passa per una buona fase pratica o di “smanettamento”, è altrettanto importante conoscere i fondamenti sintattici e teorici alla base dei linguaggi più utilizzati. Molto spesso i libri e gli ebook a tema potrebbero essere difficili da reperire o eccessivamente costosi, per cui il web diventa una fonte preziosa soprattutto se dovessero servirvi per lavoro.
Ma allora dove posso trovare guida in PDF gratis per programmare?
Puoi trovare manuali di programmazione di vario genere ai seguenti link.
I libri di programmazione che presenteremo in questa sede possono essere utili per imparare al meglio i nostri linguaggi di programmazione preferiti, trovare esempi fatti a dovere, approfondire aspetti complessi di un linguaggio che spesso, mentre ci lavoriamo, non è agevole fare. I PDF che segnaliamo qui servono pertanto a chiarire le idee ai professionisti che vorrebbero:
approfondire un linguaggio
imparare un nuovo linguaggio di programmazione da zero
potenziare le proprie conoscenze nell’ambito
trovare esempi pratici di frammenti di codice
Dove trovare ebook di programmazione gratis da scaricare
(aggiornato al 10 settembre 2022)
Una delle risorse più importanti è senza dubbio Free Programming Books – Un must per tutti gli addetti ai lavori, trovate libri di ogni genere per PHP, Java, Python e via dicendo in formato soprattutto PDF. Disponibili in italiano,in inglese che in molte altre lingue.
Poi abbiamo pure GoalKicker (CONSIGLIATO)- Sito ricchissimo di contenuti free per programmare, tra cui una guida Python di quasi 500 pagine, R, React JS e così via – I contenuti sono offerti gratis, sono accettate donazioni volontarie books.goalkicker.com
FreeComputerBooks.com – Qui trovate non solo libri sulla programmazione ma anche su matematica avanzata ed aspetti afferenti all’informatica teorica.
TeachYourselfcs.com – Ulteriori indicazioni possono essere reperite a questo altro sito.
Ulteriori libri messi gratuitamente a disposizione dagli autori in formato PDF o dalle università sono i seguenti:
L’algoritmo A* è una tecnica di ricerca di percorso che combina il concetto della ricerca in ampiezza (BFS) con l’euristica per trovare il percorso più breve tra due nodi in un grafo. Si basa sull’espansione dei nodi in base a due valori: il costo effettivo per raggiungere il nodo corrente e una stima del costo rimanente per raggiungere la destinazione desiderata.
Ecco come funziona:
Premesse:
Grafo: Si parte da un grafo con nodi e archi.
Nodo di partenza e nodo di destinazione: Indicano i nodi tra cui cercare il percorso.
Euristica: Una funzione che stima il costo rimanente dal nodo attuale alla destinazione.
Passo 1: Inizializzazione
Insieme dei nodi visitati: Inizialmente vuoto.
Coda di priorità: Si utilizza una coda che ordina i nodi in base a una combinazione di costo effettivo e stima del costo rimanente.
Passo 2: Espansione dei nodi
Scegli il nodo con il costo minore complessivo: Utilizza la coda di priorità per estrarre il nodo con il costo minore, che è la somma del costo effettivo per raggiungere il nodo e dell’euristica verso la destinazione.
Verifica se il nodo estratto è la destinazione: Se il nodo estratto è la destinazione, si è trovato il percorso più breve e si può terminare l’algoritmo.
Altrimenti, espandi il nodo estratto: Esamina tutti i nodi adiacenti al nodo estratto e calcola il costo effettivo per raggiungerli. Aggiungi questi nodi alla coda di priorità.
Passo 3: Aggiornamento dei costi
Aggiorna i costi se necessario: Se il costo effettivo per raggiungere un nodo adiacente è inferiore al costo precedente, aggiorna il costo e il percorso associato a quel nodo.
Passo 4: Ripeti finché non si raggiunge la destinazione o la coda è vuota
Continua il processo: Continua a estrarre il nodo con il costo minore finché non si raggiunge la destinazione o finché la coda di priorità non è vuota.
Passo 5: Ottieni il percorso più breve
Recupera il percorso più breve: Una volta raggiunta la destinazione, è possibile recuperare il percorso più breve seguendo i nodi precedenti memorizzati durante l’esecuzione dell’algoritmo.
Conclusione
Alla fine dell’algoritmo, si ottiene il percorso più breve tra il nodo di partenza e il nodo di destinazione, utilizzando l’euristica e l’informazione dei costi per guidare l’esplorazione del grafo.
Spiegazione in termini di “altezza” dei nodi
Introdurre un concetto di “altezza” dei nodi in A* potrebbe essere simile all’uso di un’altra euristica. L’idea è di assegnare un valore di altezza a ciascun nodo, che rappresenta una sorta di informazione aggiuntiva sulla desiderabilità o sulla probabilità di quel nodo di condurre verso la destinazione. In termini più semplici, i nodi “più alti” potrebbero essere preferiti nel percorso rispetto a quelli “più bassi”.
Per illustrare questo concetto, possiamo introdurre una funzione di altezza che assegna valori di altezza ai nodi in base alla loro posizione o ad altre caratteristiche del grafo. Ad esempio, in un terreno montagnoso, i nodi più alti potrebbero rappresentare aree più difficili da attraversare, mentre quelli più bassi potrebbero essere terreni più agevoli. Quindi, un’altezza maggiore potrebbe corrispondere a una penalità nell’algoritmo.
Implementazione in Python
In Python, l’algoritmo A* può essere implementato utilizzando una coda di priorità per gestire l’espansione dei nodi in base al costo complessivo (costo effettivo più l’euristica).
In questo esempio:
graph rappresenta il grafo con i nodi e i relativi pesi sugli archi.
La funzione heuristic calcola l’euristica tra due nodi (può essere personalizzata a seconda del problema).
La funzione astar esegue l’algoritmo A* per trovare il percorso più breve dal nodo di partenza al nodo di destinazione nel grafo fornito.
Restituisce il percorso più breve come lista dei nodi attraverso cui passa il percorso ottimale, o None se non è stato trovato alcun percorso.
Ovvero:
import heapq
def heuristic(node, goal):
# Euristicamente valuta la distanza tra il nodo corrente e il nodo di destinazione
# In questo esempio, si calcola la distanza euclidea (si può personalizzare)
x1, y1 = node
x2, y2 = goal
return ((x2 - x1) ** 2 + (y2 - y1) ** 2) ** 0.5
def astar(graph, start, goal):
# Coda di priorità per mantenere traccia dei nodi da esplorare
priority_queue = [(0, start)]
# Dizionario per memorizzare i costi effettivi per raggiungere i nodi
costs = {start: 0}
# Dizionario per memorizzare i nodi precedenti nel percorso più breve
previous = {}
while priority_queue:
current_cost, current_node = heapq.heappop(priority_queue)
if current_node == goal:
# Recupera il percorso più breve una volta raggiunta la destinazione
path = []
while current_node in previous:
path.append(current_node)
current_node = previous[current_node]
path.append(start)
return path[::-1] # Ritorna il percorso in ordine corretto
for neighbor in graph[current_node]:
# Calcola il costo effettivo per raggiungere il vicino
cost = costs[current_node] + graph[current_node][neighbor]
if neighbor not in costs or cost < costs[neighbor]:
# Aggiorna i costi e il nodo precedente se il costo è minore
costs[neighbor] = cost
priority = cost + heuristic(neighbor, goal)
heapq.heappush(priority_queue, (priority, neighbor))
previous[neighbor] = current_node
return None # Se non viene trovato alcun percorso
# Esempio di utilizzo
graph = {
'A': {'B': 5, 'C': 10},
'B': {'D': 7},
'C': {'D': 3},
'D': {}
}
start_node = 'A'
goal_node = 'D'
path = astar(graph, start_node, goal_node)
if path:
print("Il percorso più breve da", start_node, "a", goal_node, ":", path)
else:
print("Nessun percorso trovato da", start_node, "a", goal_node)
Nel successivo esempio, la funzione height assegna un valore di altezza arbitrario a ciascun nodo. Questo valore di altezza viene considerato nel calcolo del costo effettivo per raggiungere i nodi, influenzando la scelta dei percorsi durante l’esecuzione dell’algoritmo A*. È importante notare che la funzione di altezza può essere personalizzata in base alle specifiche del problema.
import heapq
def heuristic(node, goal):
# Euristica basata sulla distanza euclidea tra i nodi
x1, y1 = node
x2, y2 = goal
return ((x2 - x1) ** 2 + (y2 - y1) ** 2) ** 0.5
def height(node):
# Funzione di altezza per assegnare un valore di altezza a ciascun nodo (esempio semplice)
# In questo caso, l'altezza è un valore arbitrario associato al nodo
height_values = {
'A': 5,
'B': 2,
'C': 8,
'D': 3
# ... altri nodi e relativi valori di altezza
}
return height_values.get(node, 0) # Ritorna l'altezza associata al nodo, se presente
def astar_with_height(graph, start, goal):
priority_queue = [(0, start)]
costs = {start: 0}
previous = {}
while priority_queue:
current_cost, current_node = heapq.heappop(priority_queue)
if current_node == goal:
path = []
while current_node in previous:
path.append(current_node)
current_node = previous[current_node]
path.append(start)
return path[::-1]
for neighbor in graph[current_node]:
# Calcolo del costo effettivo per raggiungere il vicino, considerando anche l'altezza
cost = costs[current_node] + graph[current_node][neighbor] + height(neighbor)
if neighbor not in costs or cost < costs[neighbor]:
costs[neighbor] = cost
priority = cost + heuristic(neighbor, goal)
heapq.heappush(priority_queue, (priority, neighbor))
previous[neighbor] = current_node
return None
# Utilizzo dell'algoritmo A* con altezza dei nodi
graph = {
'A': {'B': 5, 'C': 10},
'B': {'D': 7},
'C': {'D': 3},
'D': {}
}
start_node = 'A'
goal_node = 'D'
path = astar_with_height(graph, start_node, goal_node)
if path:
print("Il percorso più breve da", start_node, "a", goal_node, ":", path)
else:
print("Nessun percorso trovato da", start_node, "a", goal_node)
Se vuoi sapere come installare WordPress su un pc in locale, sei arrivato nel posto giusto: in questo articolo fornirò tutti i dettagli necessari mediante una guida pratica. Va premesso che ad oggi le stesse procedure fatte direttamente su un servizio di hosting, ad esempio, potrebbero essere ancora più agevoli, per cui valutate sempre con attenzione.
A volte ci serve disporre di WordPress per varie ragioni: ad esempio a scopo di test, o per sviluppare il nostro sito prima di pubblicarlo con calma e la dovuta attenzione. Installarlo in locale è, di fatto, l’ideale per queste ultime situazioni.
Che cos’è XAMMP
XAMMP è una soluzione di software bundle, cioè una suite di programmi che include di per sè tutto quello che ci serve per fare funzionare un sito WordPress in locale. È disponibile sia in versione free (gratis per gli sviluppatori) che in versione a pagamento o in cloud, utile per l’utilizzo professionale. XAMMP è comodo perchè installa in un colpo solo:
PHP
MySQL
Apache
NGINX
I dettagli dell’articolo che vedrete i seguito sono stati aggiornati all’ultima versione di WordPress e di XAMPP; delle tante possibilità di software con PHP MySQL Apache, la nuova versione di XAMPP è molto vantaggiosa, perchè offre sia PHP di ultima generazione (con la possibilità di switchare le varie versioni) che Apache ed NGINX, volendo, che potrete testare localmente apprezzandole le prestazioni soprattutto (attenzione che va configurato a dovere che non sarà più interpretato il file htaccess).
Scaricare XAMPP
La versione di XAMPP gratuita 7.2 (quella più recente al momento in cui scrivo) va bene per la maggioranza delle esigenze più concrete. Ecco il link per scaricarla:
https://www.apachefriends.org/download.html
Scaricatela e naturalmente installatela per il vostro sistema operativo: servirà a fornirvi tutto quello che vi darebbe un servizio di hosting ma nell’autonomia e la tranquillità di un ambiente locale. Se state installando WordPress su un PC, poi, ci sono distribuzioni che già forniscono un server integrato adeguato.
WordPress con Apache server
Nello specifico, si tratta di installare e poi utilizzare Apache nella sua versione più recente (2.4 al momento in cui scrivo), con l’aggiunta del server di database MySQL (5.4, al momento) ed il motore PHP (dalla versione 7 in poi). Piuttosto che installare un pezzo per volta queste tre componenti, utilizzeremo (solo in locale, ovviamente) un componente bundle che integra tutte e tre in un colpo solo, ovvero XAMPP.
WordPress con NGINX server
In alternativa, si possono utilizzare NGINX come webserver alternativo (il che offre una serie di vantaggi, ma è molto diverso da Apache a livello di architettura), e varie versioni “alternative” di PHP e MySQL. In genere le opzioni standard di XAMPP vanno bene, il più delle volte e per la maggioranza dei casi: quindi installate tutto con le opzioni standard, senza pensarci troppo.
Per inciso, eccovi alcuni pacchetti di installazione della “triade” in questione per qualsiasi altro sistema operativo:
Alternativa per Linux: LAMP (la “triade” in questione è preinstallata nei sistemi Ubuntu, di solito)
Scaricare l’ultima versione di WordPress
Installato l’ambiente di lavoro, xome seconda cosa dovrete procurarvi l’ultima versione localizzata in lingua italiana, che potete trovare a questo indirizzo:
Andate nella pagina e cliccate sul bottone blu con su scritto “Download WordPress x.y.z” dove x, y, z sono i numeri della versione corrente. Installate sempre l’ultima versione così sarete più al sicuro rispetto a bug e falle informatiche di vario genere.
Al momento in cui scriviamo, la versione WordPress da usare è la 5.6 (o sue possibili derivazioni come 5.6.1, 5.6.2, ecc.)
Scompattare WordPress in una cartella del vostro computer
Una volta che scaricate il file (ad es. si chiamerà wordpress_it_IT_x_y_z.zip), scompattatelo nella sua stessa cartella (che può avere lo stesso nome del file wordpress_it_IT_x_y_z, anche se di norma si chiamerà /wordpress). In seguito andrete a spostare la cartella /wordpress all’interno della cartella dei file dei siti di XAMMP, che si chiamerà htdocs e che dovrà contenere /wordpress. In questo modo il sito sarà raggiungibile da http://localhost:8888/wordpress, ad esempio.
htdocs si trova in varie posizioni del sistema operativo: ad esempio se usate Ubuntu, corrisponde alla cartella
/var/www/html/
se invece usate Windows lo troverete nella cartella C:/Programmi/XAMMP, e se usate il Mac la troverete dentro la cartella compressa inclusa nel nome dell’app.
Installare WordPress in locale, sul vostro PC
Perchè WordPress possa funzionare in locale, sarà necessario avere XAMPP o XAMMP o LAMP installati: faccio l’esempio sul PC (dove il programma utile, come abbiamo visto, che integra sia server che database, si chiama XAMPP), ma su Linux e Windows le cose non sono troppo diverse.
Dopo aver installato il vostro bundle preferito, la prima cosa da capire è dove sono salvati i file del nostro sito: in questa cartella, infatti, dovremo copiare mediante copia-incolla via Gestione Risorse / Finder e simili i file di WordPress che abbiamo scaricato.
Riporto quindi alcuni esempi di localizzazione della cartella del server, ovviamente dovrete valutare nel vostro caso quale possa essere quella corretta.
Linux: Apache utilizza /var/WWW come root, oppure /var/www/html/ in alcuni casi; è fondamentale che abbiate attribuito alla cartella i permessi idonei mediante un CHMOD 775.
Windows: la cartella viene selezionata da voi in fase di installazione di Apache, e cambia leggermente in base all’installazione.
A questo punto rinominate la cartella wordpress in miositowp, espostate la cartella che avete rinominato (miositowp) nel path suggerito dai tre punti precedenti, a seconda dei casi.
Ora, dovreste vedere dal browser tale cartella digitando localhost, qualcosa del genere:
Nel mio PC c’erano sono molte altre cartelle di lavoro, che qui vengono giustamente listate all’interno della root del sito; nel vostro caso, dovreste vedere solo miositowp ed eventualmente i file nascosti di sistema metadata, project e settings (ignorateli). Per avviare l’installazione di WordPress basta cliccare su miositowp, in questo esempio.
Avvio dell’installazione di WordPress in locale
La prima schermata che vi apparirà è questa:
Vi viene premesso che WP ha bisogno di queste cinque informazioni per poter funzionare: nome del database, nome utente database (diverso dal nome utente con cui accederete al sito), password database, host del database e prefisso delle tabelle del db. Scorriamo in fondo alla pagina fino ad arrivare al bottone “Iniziamo“.
Cliccate sul bottone: vedrete comparire una finestra nella quale vi verranno “anticipati” i valori dei parametri visti poco fa cui avete bisogno. Tali parametri vengono usati da PHP per comunicare con MySQL, e ve li riporto di seguito scrivendo tra parentesi quelli che utilizzerò nella presente guida:
Nome del database (in questo es. wptest)
Nome utente del database (ad es. pippo)
Password del database (ad es. pippopass76)
Host del database (tipicamente localhost)
Prefisso tabelle (ad es. wp_, ma è consigliabile scegliere un prefisso diverso fin da subito)
Attenzione: la password in locale può essere scelta in modo relativamente più semplice, anche perchè per lavorare sul sito vi potrebbe spesso ricordarla a memoria. Quando passerete in produzione al sito online, ricordatevi di inserire password più complesse!
Aspettate ad andare avanti perchè serve un passo ulteriore, prima di procedere oltre.
Creazione di nome utente e database da phpMyAdmin
Lasciate aperta la finestra di installazione di WordPress, ed aprite una nuova finestra del browser, e digitate http://localhost/phpMyAdmin/ (attenzione a M ed A maiuscole).
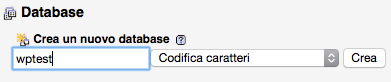
Dalla finestra che dovrebbe comparire, cliccate su “localhost” dentro la finestra, poi in alto su Database, e digitate il nome del database nella casellina dove trovate scritto, di sopra, “Crea“.
Come nome, chiaramente, dovremo inserire wptest: ecco la schermata di esempio.
Una volta creato il database, vedrete chiaramente che è vuoto: a popolarlo sarà la procedura di installazione di WordPress, per cui non vi preoccupate di fare altro, se non un altro piccolo passo.
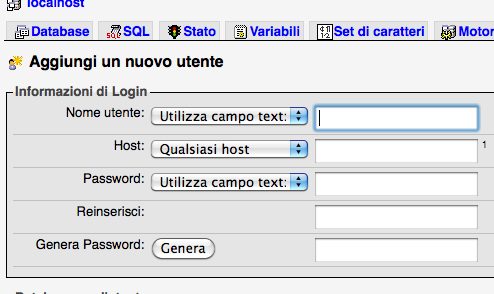
Dovrete infatti creare un utente autorizzato a leggere e scrivere nel database in questione: per farlo cliccate su Privilegi e, in basso a destra, “Aggiungi utente”. Eviteremo, infatti, di utilizzare l’utenza di root per accedere al database, visto che non è una procedura molto safe dal punto di vista della sicurezza informatica.
Ecco la schermata che dovrebbe comparire:
Siamo quasi arrivati: compilate i campi in questione, inserendo ad es. pippo come nome utente, localhost come Host (ricordatevi di inserirlo), pippopass76 come password per due volte consecutive (Password e reinserisci), e lasciate pure vuoto l’ultimo campo (a meno che, in alternativa, non vogliate che WordPress generi per voi una password casuale, cliccando per l’appunto il tasto “Genera“).
Configurazione database via phpMyAdmin
Entrate nuovamente su http://localhost/phpMyAdmin/
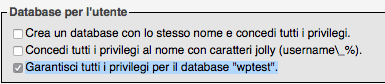
Nel campo “Database per l’utente” selezionate Garantisci tutti i privilegi per il database “wptest”.
Infine nella parte finale del form potetelimitarvi a selezionare soltanto i privilegi essenziali (le caselle sotto “Dati ” e di “Struttura” seguenti: SELECT, INSERT, UPDATE, DELETE, FILE, CREATE, ALTER, INDEX, DROP, per WordPress dovrebbero essere sufficenti).
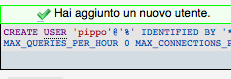
Dopo aver confermato col tasto “Esegui” in basso nella finestra, vedrete qualcosa del genere: dovrebbe apparire il messaggio “Hai aggiunto un nuovo utente“.
Adesso siete pronti per installare WordPress sul vostro PC tornando alla finestra che avevate lasciato aperta.
La compilazione dei campi richiesti da WordPress dovrebbe essere immediata, sulla base di quanto abbiamo fatto finora: per maggiore chiarezza riporto un’ulteriore immagine esplicativa.
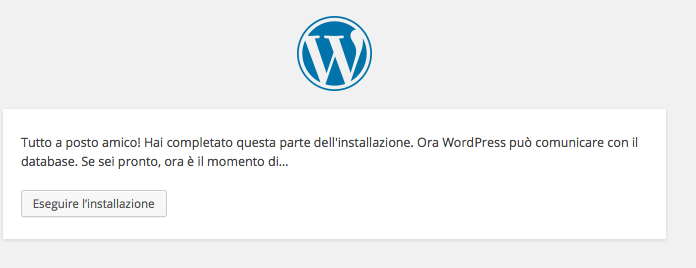
Se tutto va nel verso giusto dopo aver cliccato su “Invio“, dovrebbe comparire una nuova finestra che vi invita a continuare l’installazione, affermando che tutto è ok fino a quel momento (in pratica il file wp-config.php è stato creato correttamente). Per installare WordPress, cliccate sul bottone apposito!
Fatto questo, vi restano soltanto i campi descrittivi del blog da compilare a piacere, facendo attenzione ad inserire una vostra mail valida e soprattutto a prendere nota di username e password amministrativa dopo averle scelte. Visto che si tratta di un’installazione in locale, vi suggerisco di deselezionare la casella “Voglio che il mio sito appaia su motori di ricerca come Google e Technorati.“.
Fate click su “Esegui l’installazione“, ed avete finito!
WordPress in locale e SSL / HTTPS
In genere non trovo necessario installare HTTPS in locale, anche perchè non ha molto senso farlo – se non a scopi di sperimentazione – e, soprattutto, HTTPS deve funzionare su un servizio di hosting. Quindi tanto vale lavorare in HTTP in locale, e poi migrare il sito in HTTPS una volta in produzione sul dominio finale e dopo aver effettuato la migrazione del sito.
Farlo funzionare in locale, del resto, comporta quasi sempre l’utilizzo dei certificati auto-firmati, e si pone comunque il problema che un certificato anche gratuito con Let’s Encrypt ha comunque bisogno di un nome di dominio per poter funzionare (su localhost, in sostanza, non funzionerà ).
Per saperne di più su HTTPS, leggete l’ultima guida che ho postato nel sito.
Conclusioni
Il vostro sito WordPress in locale sarà visibile da http://localhost/miositowp, mentre l’amministrazione sarà accessibile da http://localhost/miositowp/wp-admin (oppure su http://localhost/miositowp/wp-login.php).
Attenzione perchè il prefisso dell’URL base localhost può essere cambiato da XAMPP in localhost:8888 o qualsiasi altra porta vogliate, per cui assicuratevi sempre di accedere nel modo corretto.
Il linguaggio C permette di operare a basso livello su qualsiasi programma e sistema operativo, disponendo di un livello di dettaglio molto più elevato rispetto alla tendenza dei linguaggi di programmazione che vanno per la maggiore oggi, sempre più orientati a framework e operazioni orientate agli eventi. GCC (acronimo per GNU Compiler Collection) risponde ad un’esigenza pratica: precompilare il codice sorgente in C, tradurlo in linguaggio macchina (in modo multipiattaforma, quindi funzionante su qualsiasi sistema operativo) e renderlo così file eseguibile.
In genere GCC è anche considerato poco user-friendly quanto, alla prova dei fatti, versatile ma altrettanto utile ad esempio a scopo didattico (per questo motivo viene usato nei corsi di informatica universitari che includano il linguaggio C, ad esempio). L’uso di GCC è stato promosso primariamente da Richard Stallman, fautore del software libero e principale promotore del suo uso, anche attraverso una guida molto dettagliata che ne illustrava i principi e l’ispirazione free (nel senso di software libero, non semplice software gratuito come spesso viene inteso).
Grazie a GCC possiamo disporre di front-end adeguati per tantissimi linguaggi, ad oggi, tra cui Objective C, Go, C++, Java, Ada e Fortran, e possiamo programmare sulle architetture hardware più diverse tra loro, da SPARC a PowerPC, passando per processori ARM o per i classici e più comuni x86 e x86-64.
Installare gcc su sistema operativo AIX
AIX:
Bull’s Open Source Software Archive for for AIX 6 and AIX 7;
A differenza di altri sistemi Linux-based, il sistema operativo del Mac NON supporta di default GCC, ma permette comunque di installarlo sfruttando MacPorts o Homebrew. Ho provato a farlo sul mio Mac, e superato qualche problemino che potrebbe capitare anche a voi diciamo che l’operazione sembra essere abbastanza fattibile.
Anzitutto, verificate che gcc non sia già installato con questo comando da terminale:
Windows prevede il supporto a gcc ma solo mediante Cygwin, per cui fate riferimento alla documentazione del progetto per maggiori informazioni. Nel dettaglio:
Installa Cygwin, che ci offre un ambiente simile a Unix in esecuzione su Windows.
Installa i pacchetti Cygwin richiesti per la creazione di GCC. Dall’interno di Cygwin, scarica il codice sorgente di GCC dal sito ufficiale, crealo e installalo.
a questo punto dovresti essere pronto ad usare GCC su Windows
Immagina di voler cambiare macchina, e di dover prendere una decisione su quale automobile acquistare. Come fare? Puoi ascoltare il parere del concessionario, leggere qualche rivista, guardare le opinioni su Google su ogni modello o basarti su principi molto più blandi come la forma che ti piace, oppure – ancora – considerare gli optional, la presenza di aria condizionata, il costo il il fatto che il motore sia ibrido oppure elettrico. Come regolarti in questa miriade di possibili scelte?
Potresti ad esempio utilizzare un albero decisionale per guidarti in base a diverse caratteristiche e condizioni.
Definizione albero decisionale
Un albero decisionale è un modello di apprendimento supervisionato basato su una struttura ad albero, che viene utilizzato per prendere decisioni e/o fare previsioni suddividendo ripetutamente il set di dati in base alle caratteristiche dei dati stessi. Gli alberi decisionali sono costituiti da nodi e rami, che rappresentano le decisioni e le condizioni che guidano il flusso di apprendimento.
Ecco come un albero decisionale può essere composto:
Radice: il primo nodo o nodo base dell’albero decisionale.
I rami rappresentano le possibili alternative o risultati di una decisione. I rami si estendono dai nodi e portano ad altri nodi o alle foglie.
I nodi rappresentano le decisioni o le condizioni da valutare (ciò che viene “scritto” sui rami, in pratica). Ogni nodo contiene una caratteristica o una variabile di input e una regola di divisione che definisce come suddividere il set di dati in base a quella caratteristica
Le foglie sono i nodi terminali dell’albero decisionale. Rappresentano le etichette di classe o le previsioni finali. Ogni foglia corrisponde a una classe o a un valore di output.
Una regola di divisione specifica come il set di dati viene suddiviso in base a una caratteristica. Ad esempio, se una caratteristica è numerica, una regola di divisione potrebbe essere “valore <= 10”, che indica che i dati con un valore inferiore o uguale a 10 verranno indirizzati verso un ramo specifico, e gli altri per esclusione sull’altro.
La profondità di un albero decisionale rappresenta il numero di nodi attraversati da un percorso dalla radice a una foglia. Una profondità maggiore indica un albero decisionale più complesso e potenzialmente più specializzato.
Ecco un esempio di quello che intendiamo per l’esempio della macchina:
La radice dell’albero decisionale potrebbe essere “Tipo di automobile da acquistare”.
I nodi rappresentano le decisioni o le condizioni da valutare. Ad esempio, un nodo potrebbe essere “Budget a disposizione”, “colore preferito”, “marca della macchina che usa il collega che invidio”.
I rami rappresentano le alternative o le “conseguenze” delle nostre decisioni. Ad esempio, se il budget disponibile è alto, potresti avere un ramo che porta a “Automobili di lusso” e un altro ramo che porta a “Automobili convenzionali”.
Foglie: Le foglie rappresentano le decisioni finali. Ad esempio, una foglia potrebbe essere “Acquista un’automobile di lusso” o “Acquista un’automobile convenzionale”.
Regola di divisione: La regola di divisione specifica come il set di dati viene suddiviso. Ad esempio, se il budget disponibile è superiore a una determinata soglia, potrebbe essere suddiviso in “Alto” e “Basso” per guidare la scelta tra automobili di lusso o automobili convenzionali.
La complessità dell’argomento è evidente se si pensa che abbiamo sempre un budget limitato, e che la scelta è condizionata da fattori non per forza legati alla qualità della stessa (difetti congeniti nelle auto, chiacchiere da ufficio, valutazioni esteriori non di natura tecnica, suocere, …). In alternativa, potresti prendere altre decisioni basate su caratteristiche come il consumo di carburante, il numero di passeggeri, la marca, ecc., utilizzando ulteriori nodi e rami per arrivare a una decisione finale.
L’albero decisionale nel mondo reale ti aiuta a prendere decisioni organizzate, guidandoti attraverso le diverse caratteristiche e condizioni rilevanti per il problema che stai affrontando. Può semplificare il processo decisionale fornendo una struttura chiara e gerarchica.
Come funziona l’albero decisionale
La costruzione di un albero decisionale coinvolge l’utilizzo di algoritmi di apprendimento specifici, come l’algoritmo CART (Classification and Regression Trees) o l’algoritmo ID3 (Iterative Dichotomiser 3). Questi algoritmi utilizzano criteri di misura dell’impurità, come ad esempio l’entropia, per selezionare la miglior caratteristica di divisione in ogni nodo, passo dopo passo. L’albero decisionale viene costruito in modo ricorsivo, dividendo il set di dati in base alle caratteristiche selezionate fino a quando viene raggiunto un criterio di stop, ad esempio una profondità massima o un numero minimo di campioni in una foglia.
L’obiettivo dell’addestramento di un albero decisionale è quello di creare una struttura che sia in grado di generalizzare bene su nuovi dati, catturando le relazioni e le decisioni all’interno del set di dati di addestramento.
Alberi decisionali in Python: RandomForestClassifier
RandomForestClassifier è un algoritmo di apprendimento supervisionato che appartiene alla famiglia degli alberi decisionali ed è utilizzato per la classificazione. È implementato nella libreria scikit-learn di Python. Un albero decisionale è pertanto un modello di apprendimento che prende decisioni o stima l’etichetta di una classe, suddividendo ripetutamente il set di dati in base alle caratteristiche dei dati. RandomForestClassifier estende questa idea creando un insieme (ensemble) di alberi decisionali e utilizzando la votazione della maggioranza per fare previsioni.
Il processo di creazione di un RandomForestClassifier coinvolge i seguenti passaggi:
Creazione degli alberi: vengono creati diversi alberi decisionali utilizzando un processo chiamato “bagging”. Il bagging coinvolge la creazione di campioni casuali (bootstrap) dal set di dati di addestramento e l’addestramento di alberi decisionali su questi campioni.
Divisione dei nodi: durante la costruzione degli alberi decisionali, in ogni nodo viene selezionata casualmente una sottoinsieme delle caratteristiche (feature) disponibili. Questo processo è chiamato “splitting casuale”. Viene selezionata la migliore caratteristica di split tra quelle selezionate in modo casuale.
Votazione della maggioranza: dopo aver creato tutti gli alberi decisionali, durante la fase di previsione, ciascun albero fa una previsione e viene utilizzata la votazione della maggioranza per determinare la classe finale assegnata dal RandomForestClassifier.
RandomForestClassifier offre diversi vantaggi rispetto agli alberi decisionali singoli. Essendo un ensemble di alberi, può gestire meglio il rumore e la varianza nei dati, riducendo il rischio di overfitting. Inoltre, può gestire grandi set di dati e caratteristiche non lineari. Inoltre, fornisce anche una stima dell’importanza delle caratteristiche, che può essere utile per l’analisi dei dati.
Esempio pratico
Per utilizzare RandomForestClassifier in scikit-learn, è necessario importare la classe RandomForestClassifier dalla libreria sklearn. Quindi, è possibile creare un’istanza del modello, addestrarlo sui dati di addestramento utilizzando il metodo fit(), e fare previsioni utilizzando il metodo predict().
Ecco un esempietto di codice per utilizzare RandomForestClassifier in Python:
from sklearn.ensemble import RandomForestClassifier
# Creare un’istanza di RandomForestClassifier
model = RandomForestClassifier()
# Addestrare il modello sui dati di addestramento
model.fit(X_train, y_train)
# Fare previsioni sui dati di test
y_pred = model.predict(X_test)
Nell’esempio sopra, X_train e y_train rappresentano i dati di addestramento, mentre X_test è il set di dati su cui fare le previsioni. Dopo l’addestramento, le previsioni vengono fatte utilizzando il metodo predict() e memorizzate in y_pred. (immagine di copertina: un albero immaginato da StarryAI)
Come verificare la validità di un certificato HTTPS in Python – Check HTTPS in Python
Con un semplice script python è possibile verificare la validità del certificato SSL per uno specifico host. La lista del materiale occorrente comprende una versione di Python aggiornata, in questa guida si farà riferimento alla 3.8 e i seguenti moduli, installabili via pip:
pyopenssl
idna
cryptography
Per prima cosa bisogna creare un socket che si connetta all’host da esaminare:
socket = socket()
socket.connect(('esempio.com', 443))
si crea ora il context SSL passando come parametro la versione SSL, utilizzeremo la versione SSLv3 che è una delle più comuni, se ciò non dovesse funzionare a questo link troverete una lista dei parametri da poter dare in ingresso.
cntx = SSL.Context(SSL.SSLv23_METHOD)
diamo istruzioni per stabilire una secure socket connection
idna.encode('esempio.com') codifica in Punycode l’argomento che gli si passa, in questo caso esempio.com.
do_handshake() esegue l’SSL handshake.
Si deve ora recuperare il certificato crtf = sock_ssl.get_peer_certificate() e accedere alle informazione di questo, decrittografandolo e rendendolo human readible: dcrpt_crtf =crtf.to_cryptography()
Si possono estrapolare tutte le informazioni dal certificato:
Subject Alternate Name (SAN) : dcrpt.extensions.get_extension_for_class(x509.SubjectAlternativeName)
Common Name (CN) : dcrpt.subject.get_attributes_for_oid(NameOID.COMMON_NAME)
se il certificato è valido si otterrà un output del genere <urllib3.response.HTTPResponse object at 0x7fd3ca5da580>, simile all’output di sock_ssl.get_peer_certificate().
Se non è valido otterremo un’eccezione del tipo urllib3.exceptions.SSLError.
Geolocalizzare un IP in Python
La localizzazione geografica di un indirizzo IP in python è alquanto semplice, è necessaria l’installazione del solo modulo requests.
Ovviamente al posto di indirizzoIP, va inserito un indirizzo. Si otterrà un json con le informazioni richieste
{‘country_code’: ‘IT’, ‘country_name’: ‘Italy’, ‘city’: ‘Roma’, ‘postal’: ‘ 00118‘, ‘latitude’: 41.9028, ‘longitude’: 12.4964, ‘IPv4’: ‘indirizzoIP’, ‘state’: ‘Provincia di Roma’}
Pingare un sito in python
il modo più veloce per effettuare un ping usando il linguaggio python è installare pythonping.
Fatto ciò, non rimane che importarlo e lanciarlo, pingando un sito:
from pythonping import ping
ping('sito.com')
questo restituirà una liste con le risposte, contenti il pacchetto ricevuto e altre meta informazioni.
Un altro modo è quello di usare i comandi del sistema operativo da uno script python:
import os os.system(f"ping -c 1 -w2 'sito_da_pingare.com' > /dev/null 2>&1 ") se usate Linux os.system(f"ping -n 1 -w2 'sito_da_pingare.com' > /dev/null 2>&1 ") se usate Windows
Gestisci Consenso
Per comprendere il flusso di utenti e poter garantire una migliore esperienza d'uso utilizziamo un unico cookie per l'analisi del traffico web. Ci teniamo alla tua privacy e non raccogliamo nulla che non ci interessa e non cediamo nessun dato. Per saperne di più leggi la nostra Privacy Policy.
Funzionale
Sempre attivo
L'archiviazione tecnica o l'accesso sono strettamente necessari al fine legittimo di consentire l'uso di un servizio specifico esplicitamente richiesto dall'abbonato o dall'utente, o al solo scopo di effettuare la trasmissione di una comunicazione su una rete di comunicazione elettronica.
Preferenze
L'archiviazione tecnica o l'accesso sono necessari per lo scopo legittimo di memorizzare le preferenze che non sono richieste dall'abbonato o dall'utente.
Statistiche
Cookie necessario al corretto funzionamento di Matomo Analytics per l'anali del traffico web.L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici anonimi. Senza un mandato di comparizione, una conformità volontaria da parte del vostro Fornitore di Servizi Internet, o ulteriori registrazioni da parte di terzi, le informazioni memorizzate o recuperate per questo scopo da sole non possono di solito essere utilizzate per l'identificazione.
Marketing
L'archiviazione tecnica o l'accesso sono necessari per creare profili di utenti per inviare pubblicità, o per tracciare l'utente su un sito web o su diversi siti web per scopi di marketing simili.