Un errore semantico si colloca generalmente nel contesto della programmazione, e si riferisce a una logica errata che porta a risultati non desiderati, nonostante il codice sia sintatticamente corretto e venga eseguito. Rilevare e correggere questi errori richiede una comprensione profonda della logica del programma e degli obiettivi che si intendono raggiungere, e spesso non ci sono criteri applicabili in generale: si usano infatti un mix di logica, esperienza e buonsenso.
In informatica, gli errori semantici (o logici) sono errori nel codice sorgente di un programma che causano un comportamento non desiderato, nonostante il programma possa essere sintatticamente corretto. Questo tipo di errore si colloca nel contesto della programmazione e dello sviluppo software, dove il codice deve non solo rispettare le regole sintattiche del linguaggio di programmazione, ma anche produrre i risultati attesi in base alla logica implementata.
Quando si verifica un errore di questo tipo (esempio)
In generale l’errore semantico (dal greco sss) si verifica quando usiamo male gli elementi che abbiamo a disposizione in un linguaggio di programmazione, ma potrebbero verificarsi anche in lingua italiana. Questi esempi illustrano come gli errori semantici possono compromettere la chiarezza e la comprensibilità del linguaggio, causando fraintendimenti o rendendo le frasi incoerenti.
Uso improprio delle parole: Frase: “Il cane miagola nel giardino.”
Spiegazione: Il verbo “miagola” è semanticamente errato perché i cani abbaiano, mentre i gatti miagolano.
Antropomorfismo errato: Frase: “Il computer è arrabbiato perché non gli piace il programma.”
Spiegazione: I computer non hanno emozioni. Questa frase è semanticamente errata perché attribuisce emozioni umane a un oggetto inanimato, per quanto possa essere usata per fornire esempi comprensibili o durante una spiegazione o un talk specialistico.
Ambiguità semantica: Frase: “Il professore ha parlato con lo studente del problema.”
Spiegazione: Non è chiaro se “del problema” si riferisca al professore o allo studente, creando ambiguità.
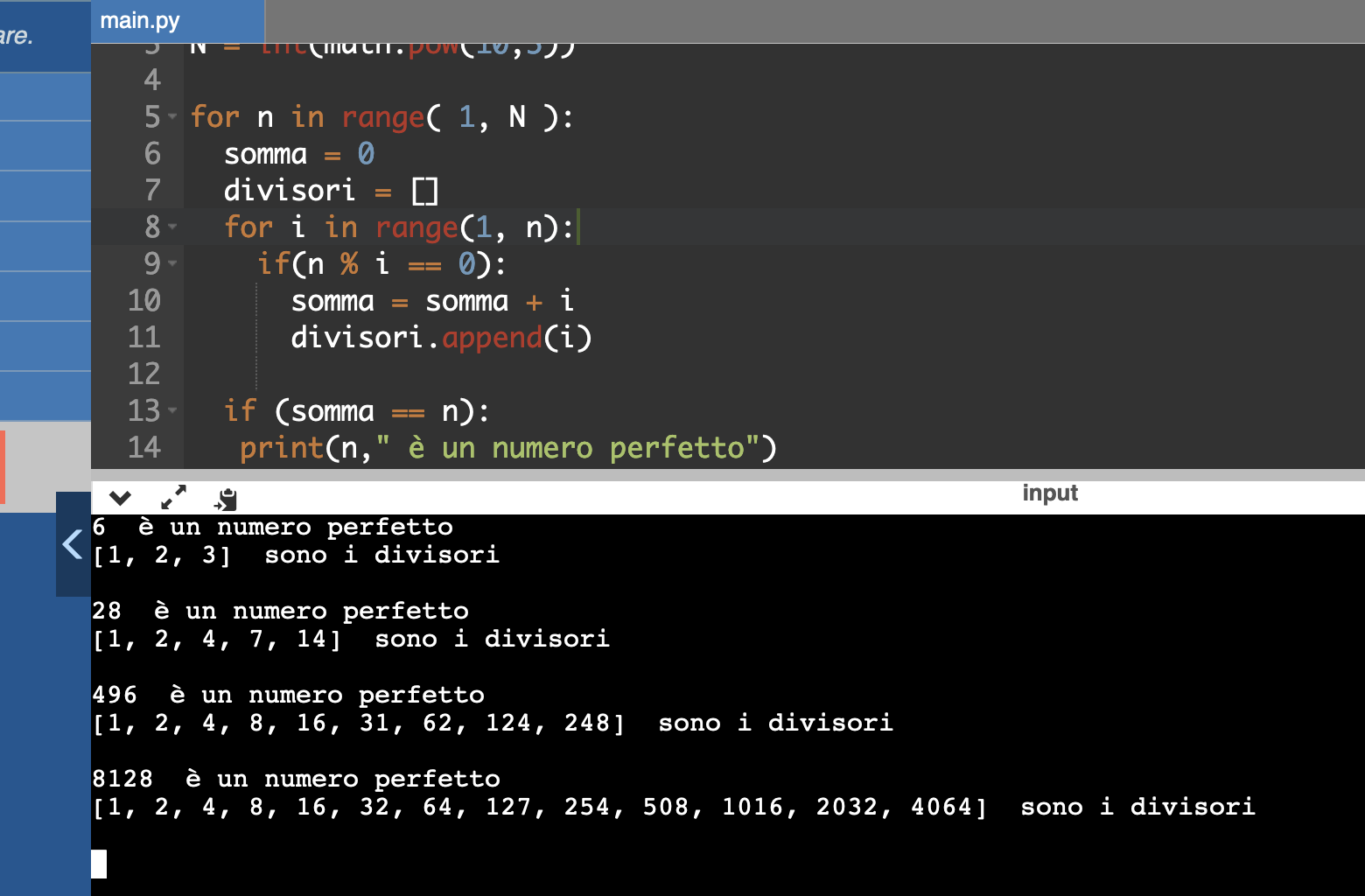
Immaginiamo adesso di voler scrivere una funzione che calcola la somma dei primi n numeri naturali. Un errore semantico potrebbe facilmente verificarsi se sbagliamo la logica della somma. Non è difficile immaginare che la somma debba andare da 1 fino ad n, passando per 2, 3, 4 , … n-2, n-1, ma un conto è pensarlo altro conto è tradurlo in termini di codice software.
Un errore semantico si verifica pertanto quando un programma non si comporta come previsto, spesso sulla base di fraintendimenti di contesto, di modalità e di significato. Questi errori in effetti sono a volte difficili da rilevare automaticamente, perché il codice sembra tecnicamente corretto dal punto di vista della sintassi, e nonostante questo il programma produce risultati sbagliati perché la logica applicata non è quella giusta. Ad esempio, poniamo di voler calcolare la somma dei primi n numeri interi a partire da zero, quindi se n=5 vogliamo ottenere 1+2+3+4+5 = 15.
Il problema è facile da risolvere in linguaggio Python, ad esempio in questi termini:
def somma_primi_n_numeri(n):
somma = 0
for i in range(1, n + 1):
somma += i
return somma
# Chiamata della funzione
n = 5
print(f"La somma dei primi {n} numeri naturali è: {somma_primi_n_numeri(n)}")
un programmatore inesperto potrebbe, ad esempio, commettere l’errore semantico di non considerare che la funzione range spazza i valori dal primo fino al secondo parametro più uno, per cui potrebbe scrivere la terza riga del codice come segue:
for i in range(1, n):
in tal caso il codice eseguirebbe lo stesso senza errori sintattici, ma il risultato per n=5 sarebbe 11 e non 15 (e sarebbe quindi sbagliato).
Altri tipi di errori semantici classici
Ecco una lista di errori semantici comuni che possono verificarsi in una singola riga di codice:
Utilizzo di variabili non inizializzate.
Divisione per zero.
Utilizzo di un operatore errato (ad esempio, * invece di +).
Accesso a un indice fuori dai limiti di un array.
Confronto errato tra variabili (ad esempio, = invece di ==).
Uso di una funzione con parametri sbagliati.
Errato casting di tipi di dati.
Modifica involontaria di una variabile globale all’interno di una funzione.
Concatenazione errata di stringhe e numeri senza conversione.
Logica condizionale sbagliata in un’istruzione if.
Questi errori possono far sì che un programma si comporti in modo inatteso o produca risultati errati nonostante il codice sia sintatticamente corretto.
Differenza tra errori sintattici e semantici
Gli errori semantici si differenziano dagli errori sintattici, che sono violazioni delle regole grammaticali del linguaggio di programmazione e vengono rilevati dal compilatore o dall’interprete durante la fase di analisi sintattica.
Stando alla pianificazione ufficiale diffusa nel sito PHP.net, la versione 8 del linguaggio per il web più utilizzato e popolare al mondo dovrebbe andare in release pubblica a dicembre 2020; in questa data, infatti, dovrebbe vedere la luce la prima versione stable. Di conseguenza, ci si aspetta che i vari servizi di hosting vadano ad adeguarsi alla nuova versione del linguaggio già verso la metà del prossimo anno.
PHP 8 è anche oggetto di un talk di Sebstian Bergmann, che entra nel merito con dettagli tecnici e performativi rispetto a questa nuova ed attesissima versione del linguaggio. Tra le novità più attese, l’introduzione di nuove interfacce e funzioni per il DOM PHP, l’introduzione di nuove funzioni di pattern matching e debug, l’uso del compilatore JIT di default, attributi per le variabili e nuovi tipi di costruttori per le classi.
Compilatore Just In Time (JIT)
Le novità di PHP 8 passano anzitutto per l’introduzione e consolidamento di un compilatore Just-In-Time, che era già disponibile dalla versione 7.4 del linguaggio (e che ho già sperimentato con successo nell’ambito dell’implementazione di OPCache). In genere un compilatore just-in-time (JIT) permette un tipo di compilazione del codice scritto in PHP più veloce e performante, in quanto viene ridotto notevolmente il tempo necessario per l’esecuzione degli script e la generazione di un bytecode più veloce da eseguire rispetto al caso ordinario.
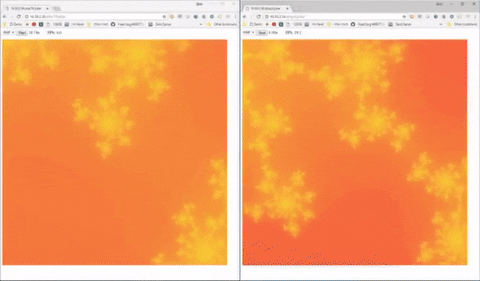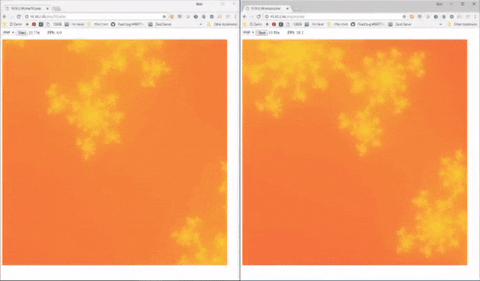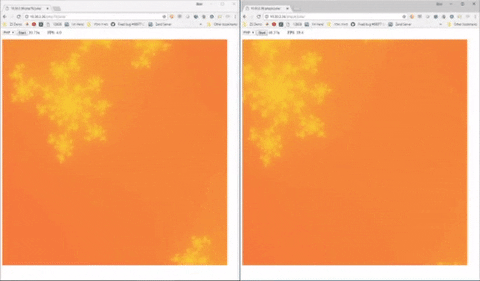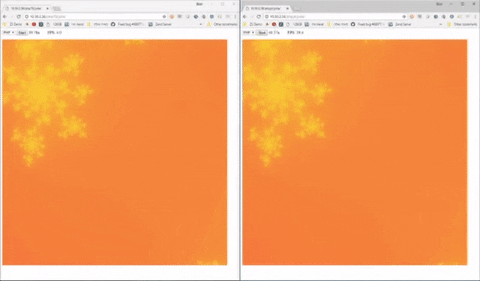
Con la versione PHP 8 tutto questo farà un ulteriore passo avanti, per quando (stando alle specifiche ufficiali) non è detto che WordPress e CMS simili scritti in PHP ne riescano ad usufruire facilmente. I test di benchmark sul JIT, di fatto, sono effettuati e apprezzabili soltanto nel caso in cui il codice venga sfruttato per la generazione di frattali, o comunque per sfruttare determinate caratteristiche del linguaggio PHP che non sempre, lato web, vengono utilizzate.
Sulla sinistra, in questo esempio (fonte) è possibile vedere una generazione di frattali con PHP standard, più lenta e “a scatti”, mentre a destra si può vedere l’elaborazione più fluida ottenibile con l’integrazione di un compilatore JIT.
Una novità che, a conti fatti, rischia un po’ di essere un uovo di colombo (quel benchmarch è visualmente efficace ma difficile da applicare nella pratica dei siti web, alla fine), senza contare che per gli informatici non è nemmeno una novità colossale (la modalità JIT esisteva già su vari linguaggi e framework da anni, e non sarà certo una salvezza per chi poi dovrà effettuare debug e manutenzione del codice). Porta sicuramente vantaggi interessanti in potenziale, ma il rischio è che la corsa all’aggiornamento si riveli più problematica che altro.
Pattern matching ottimizzato
Chiunque debba effettuare la ricerca di un pattern in una stringa sa bene quanto l’operazione, formalmente semplice sulla carta, possa rivelarsi complessa all’atto pratico. Storicamente il pattern matching tra stringhe si può effettuare mediante regex (espressioni regolari) oppure mediante strpos, che pero’ ha una sintassi francamente un po’ ostica da comprendere e ricordare.
PHP 8 ha introdotto una nuova funzione:
str_contains($ago, $pagliaio )
che restituisce true o false se la stringa $ago è contenuta nel $pagliaio. Per cercare all’inizio e solo alla fine di una stringa, similmente, sono introdotte le funzioni:
che restituiscono sempre un valore boolean true o false.
Constructor Property Promotion
Questa feature permette al programmatore PHP di risparmiarsi righe di codice, inserendo direttamente le proprietà da modificare (campi di variabili private) all’interno del costruttore della classe, per cui una classe del genere, vagamente ridondante nella sua definizione:
A partire dalla versione 8 di PHP, saranno disponibili gli attributi per le variabili, da inserire nel codice nella forma:
<<attributo>>
Debug: throw e rilevazione in real time del tipo di una variabile
Storicamente il tipo di una variabile PHP poteva essere rilevato a runtime mediante instanceof:
if(($xinstanceofFoo) ){// se $x è un oggetto di tipo Foo, fai robe...}
con PHP 8 si può usare in combinazione con la nuova funzione get_debug_type:
if( !($x get_debug_type Foo) ){
// se $x NON è un oggetto di tipo Foo
echo "oggetto x di tipo: ". get_debug_type($x);}
Sempre a livello di debug, con PHP 8 è possibile usare la funzione throw in modo più autonomo, come se fosse una funzione stand alone, e non solo in caso di specifiche Exception.
Uso dei trait con firma digitale
Si propone un uso più uniforme dei trait PHP, sfruttando le indicazioni di un nuovo RFC che esprime la necessità di firmare digitalmente le chiamate ad un metodo contenuto in un trait, lanciando eventualmente un’eccezione specifica in caso di violazioni.
Uso delle interface con firma digitale
Si fa un discorso simile a quello visto per i trait, solo che qui varrà per le interfacce (interface) delle classi.
Indici negativi consecutivi
Viene inserito by default il fatto che se inizializzo un array con indice negativi, i successivi indici utilizzati – ad esempio in caso di uso della funzione push() – possano essere sfruttati non più a partire da 0, bensì dai numeri successivi. AD esempio se inserisco un elemento in posizione -7, gli altri inserimenti saranno in corrispondenza di -6, -5 e -4.
PHP 8 supporterà gli Union Types, ovvero le variabili o i record che possono assumere uno o più tipi (ad esempio float o integer), consentendo così una maggiore flessibilità in fase di programmazione.
Ulteriori novità
Sono previsti infine un supporto migliorato per le weak maps, nuova sintassi ::class ammessa nel linguaggio, errori di tipo ottimizzati, possibilità di concludere l’elenco di parametri di una funzione con una virgola. (fonte: wiki.php.net)
Oggiamo proviamo a progettare un videogioco semplice in Java: “Indovina il numero”. Funziona da terminale. Il computer sceglie un numero casuale, tu provi a indovinarlo.
Obiettivo del gioco
Il computer genera un numero segreto tra 1 e 100
Tu provi a indovinare
Dopo ogni tentativo, il gioco ti dice se il numero è troppo alto, troppo basso, o giusto
Codice completo — IndovinaNumero.java
(Trovi una copia del codice anche qui su gdb compiler)
import java.util.Scanner;
import java.util.Random;
public class IndovinaNumero {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
Random rand = new Random();
int numeroSegreto = rand.nextInt(100) + 1; // numero da 1 a 100
int tentativi = 0;
boolean indovinato = false;
System.out.println("Benvenuto in 'Indovina il numero'!");
System.out.println("Ho scelto un numero tra 1 e 100. Riuscirai a trovarlo?");
System.out.println("Se vuoi arrenderti, scrivi 'mi arrendo'.");
while (!indovinato) {
System.out.print("Inserisci il tuo numero o 'mi arrendo': ");
String inputUtente = input.nextLine().trim();
if (inputUtente.equalsIgnoreCase("mi arrendo")) {
System.out.println("Hai scelto di arrenderti. Il numero segreto era: " + numeroSegreto);
break;
}
try {
int tentativo = Integer.parseInt(inputUtente);
tentativi++;
if (tentativo < numeroSegreto) { System.out.println("Troppo basso!"); } else if (tentativo > numeroSegreto) {
System.out.println("Troppo alto!");
} else {
System.out.println("✅ Complimenti! Hai indovinato in " + tentativi + " tentativi.");
indovinato = true;
}
} catch (NumberFormatException e) {
System.out.println("Input non valido! Inserisci un numero oppure 'mi arrendo'.");
}
}
input.close();
}
}
Il programma genera un numero segreto casuale da 1 a 100 e chiede all’utente di indovinare inserendo un numero o scrivendo “mi arrendo” per rinunciare.
Ad ogni input, letto come stringa, verifica se l’utente si arrende e in tal caso mostra il numero segreto e termina, altrimenti prova a convertire l’input in un numero intero, incrementa il contatore dei tentativi e confronta il tentativo con il numero segreto, dando indicazioni se è troppo basso o troppo alto, o congratulandosi se è esatto.
Se l’input non è né un numero valido né il comando di resa, il programma segnala un errore e richiede un nuovo tentativo, continuando il ciclo fino a indovinare o arrendersi.
Cosa si intende con machine learning? Il machine learning (apprendimento macchina, nel senso di apprendimento automatico) è un campo dell’intelligenza artificiale (AI) che si occupa dello sviluppo di algoritmi e modelli che consentono ai computer di apprendere dai dati in modo da migliorare le prestazioni nel tempo, senza dover essere esplicitamente programmato per ogni singola situazione. Per dirla in estrema sintesi, il machine learning permette ai computer di “imparare” dai dati e trarre conclusioni o prendere (alla lunga) decisioni “quasi” autonome.
Esempi di machine learning
Sebbene il machine learning sia strettamente collegato all’elaborazione dei dati e alla programmazione informatica, oltre ad avere una serie di formalismi matematici che non ne facilitano certo l’apprendimento (almeno non in prima istanza), ci sono alcuni esempi in cui possiamo vedere l’applicazione dei principi del machine learning nella pratica quotidiana senza necessariamente fare riferimento ai computer. Ecco alcuni esempi che abbiamo reperito:
Apprendimento delle abilità motorie: il concetto di machine learning può essere applicato nell’apprendimento di abilità motorie come guidare una bici o suonare un pianoforte. Inizialmente, potresti commettere errori e provare diverse azioni. Man mano che acquisisci esperienza, il tuo cervello elabora i feedback sensoriali e impara a correggere i movimenti per raggiungere, con esercizio e costanze, sempre maggiore precisione e fluidità.
Apprendimento di una lingua: quando si impara una lingua straniera, il processo di acquisizione delle parole, delle regole grammaticali e delle pronunce può essere considerato un processo di machine learning. Inizialmente, si fanno errori e si prova a costruire frasi in modo approssimativo. Con l’esposizione continua e la pratica, si migliora progressivamente la padronanza della lingua e si diventa più fluenti.
Riconoscimento dei modelli: un agricoltore potrebbe imparare a riconoscere i segnali che indicano la presenza di malattie sulle piante o un sommelier potrebbe sviluppare la capacità di distinguere diversi aromi e sapori nel vino.
Adattamento al cambiamento: Il concetto di adattamento al cambiamento nell’esperienza umana può essere considerato come una forma di machine learning. Quando ci troviamo di fronte a nuove situazioni o sfide, il nostro cervello elabora l’esperienza passata, impara dai successi e dagli errori, e si adegua per affrontare in modo più efficace i nuovi scenari, facendo ipotesi di vario genere e comportandosi sulla base dell’esperienza e dei propri desideri.
Sebbene questi esempi siano semplici analogie parziali per illustrare come il machine learning possa riflettere il processo di apprendimento umano, è importante notare che l’effettiva implementazione e applicazione di questo tipo di algoritmi richiede il supporto di algoritmi e tecniche computazionali avanzate.
A livello pratico – Nel caso in esame, faremo uso della libreria di Python Sci-Kit, che ci aiuterà a comprendere meglio il nostro argomento.
Esempi più pertinenti si possono snocciolare in modo induttivo: quando si visita un sito di shopping online, come Ebay o Amazon, il sistema utilizza algoritmi di machine learning per analizzare i tuoi precedenti acquisti, le tue preferenze, le recensioni degli altri utenti, i prodotti che hai visitato più spesso e le ricerche che hai fatto in passato. In questo modo utilizza queste informazioni per suggerire prodotti che potrebbero interessarti. Ad esempio, se hai acquistato un paio di scarpe da corsa, potresti ricevere suggerimenti su altri articoli correlati, come calze sportive o abbigliamento da fitness. I suggerimenti per le serie e i film su Amazon Video o Netflix possono, in teoria, seguire lo stesso principio. Gli articoli che potete vedere alla fine di ogni articolo del nostro blog, per fare un ulteriore ultimo esempio, possono considerarsi una forma di suggerimento di contenuti basato sull’apprendimento macchina, questa volta applicato ai contenuti testuali.
Storia del machine learning
La storia del machine learning risale agli anni ’40 e ’50, quando i primi pionieri dell’informatica, come Alan Turing, si interessarono alla possibilità di creare macchine capaci di apprendere. Tuttavia, fu solo negli anni ’60 che il concetto di machine learning iniziò ad essere sviluppato in modo più concreto. Nel 1959 Arthur Samuel, uno dei pionieri del campo, introdusse il termine “machine learning” e sviluppò un programma di gioco per dama che imparava dai suoi errori e migliorava le sue mosse nel tempo. Questo lavoro pionieristico ha posto le basi per molte delle tecniche di machine learning utilizzate oggi.
Negli ultimi anni, con l’avvento del “big data” e dei progressi nella capacità di elaborazione dei computer, il machine learning è diventato sempre più pervasivo. Algoritmi complessi come le reti neurali profonde (deep neural networks) hanno raggiunto risultati impressionanti in campi come il riconoscimento delle immagini, la traduzione automatica, il riconoscimento vocale e molti altri. Oggi, il machine learning è presente in numerosi settori, tra cui l’industria, la medicina, la finanza, la ricerca scientifica e molti altri. Continua a evolversi rapidamente grazie a nuove tecniche, algoritmi più sofisticati e ad approcci innovativi, come il reinforcement learning oppure il transfer learning. Molti passi sono stati compiuti fino ad oggi e, di fatto, grazie allo sviluppo di linguaggi e librerie open source gran parte di queste tecniche sono disponibili per qualsiasi azienda e programmatore volesse farne uso.
Statistica, analisi e “direzionalità” dei dati
Tanto per fissare subito le idee e non scendere in eccessivi dettagli che renderebbero la trattazione quasi impossibile (nonchè dispersiva), poniamo che i nostri dati siano rappresentabili su un piano cartesiano. Ad esempio stiamo raccogliendo informazioni su temperatura e altitudine di un territorio, per cui i nostri dati sono rappresentabili come una “nuvola” di punti così rappresentabile. Una nuvola perchè, proprio come le nuvole in cielo, non c’è una forma ben definita, tanto che la loro rappresentazione è tipicamente soggettiva e molte persone vedono forme nelle nuvole che altri, diversamente, non riescono a vedere (fenomeno noto come pareidolìa, per inciso).
In questo caso facciamo caso, per i nostri scopi, esclusivamente alla forma “generale” della nuvola, dove i punti più densi sono più scuri e quelli meno densi più chiari: anche senza avere un dottorato in matematica (avercene…) è abbastanza chiaro che non sia possibile definire una funzione matematica che permetta di rappresentare in modo sintetico la distribuzione di punti, come avverrebbe per disegnare invece una retta, una parabola o una circonferenza (che difficilmente fitterebbero, ovvero corrisponderebbero, in ogni casi, a dati del mondo reale). Lei irregolarità / imprevedibilità del mondo di ogni giorno sono il primo vero ostacolo che si incontra quando si lavora con il machine learning (…e quando si vive, aggiungerei 🙂 ): e allora come procedere? Come possiamo approcciare ad un problema del mondo reale per cui non esiste una formalizzazione matematica classica, di quelle che si studiano a scuola o nei primissimi anni di università?
La statistica in questo caso può essere di aiuto, ed è evidenziata dalle due frecce perpendicolari che sono disegnate nella figura in basso che abbiamo tratto da Wikipedia: se ci fate caso le due frecce puntano nella direzione di maggiore densità dei dati, ed è stato in questo modo possibile definirla una certa direzionalità. Non si tratta di un avere propria direzione, perché di fatto non c’è una direzione netta nella distribuzione di quei dati: c’è una direzionalità, un concetto differente, più vago se vogliamo ma anche più adeguato ad esprimere quello che ci serve. I vettori (le freccette) indicati/e in figura, da un punto di vista tecnico, sono detti autovettori della matrice di covarianza, e sono alla base della disciplina nota come analisi delle componenti principali.
Lo scopo di questo genere di analisi dei dati è proprio quello di fissare una direzionalità dei dati sparsi, semplificandone la trattazione senza, al contempo, perdere troppe informazioni a riguardo. Quelle due freccette ci dicono che i dati tendenzialmente si addensano in quelle due direzioni, senza entrare in troppi dettagli e fornendo una descrizione ad alto livello degli stessi.
Varianza e covarianza
Senza perderci in ulteriori digressioni, torniamo sulla parola covarianza, per un attimo. Un concetto statistico non difficile da definire ma importante da fissare. Per quello che ci interessa, ci teniamo stretto il concetto di varianza e covarianza, che in statistica indicano rispettivamente :
La varianza è una misura della dispersione dei dati rispetto alla loro media. Indica quanto i dati si discostano dai loro valori medi. Una varianza bassa indica che i dati sono concentrati intorno alla media, mentre una varianza alta indica una maggiore dispersione dei dati.
La covarianza, d’altra parte, è una misura della relazione lineare tra due variabili. Misura la direzione e la forza della relazione tra le variabili. Una covarianza positiva indica che le due variabili tendono a variare nello stesso senso, mentre una covarianza negativa indica che le due variabili tendono a variare in direzioni opposte.
La media aritmetica di 10 dati è data, in forma base, dalla somma dei 10 dati divisa per 10, per quanti sono i dati. La varianza si calcola, per inciso, come la media dei quadrati delle differenze tra ciascun dato e la media dei dati.
Per intenderci, se due set di dati (uno rosso e l’altro blu, in figura) hanno entrambi media sul valore 100, possono avere due varianze diverse: quella blu è più bassa e quella rossa è più alta, il che significa che nel caso dei dati rossi ci sono più dati addensati su una media che è vicina al cento, mentre la distribuzione blu risulta più uniforme. Due varianze diverse pur avendo la stessa media, in sostanza.
La varianza gioca un ruolo fondamentale per molti algoritmi di machine learning, ed è per questa ragione che l’abbiamo introdotta.
Tecnica di model fitting
Poniamo di aver acquisito i nostri dati e di averli sparsi come tanta sabbiolina sopra un piano. Ogni chicco di sabbia rappresenta un puntino nel grafico che abbiamo visto all’inizio, ed abbiamo visto che è possibile effettuare una misurazione della sua varianza allo scopo di determinare la “densità” dei dati in prossimità della media degli stessi. Che cosa succede se aggiungiamo della sabbia in termini di algoritmo? L’algoritmo sarai in grado di riconoscere la direzionalità di nuovi dati che vengono sottoposti? La tecnica di model fitting (adeguamento del modello) è un processo iterativo che coinvolge la sperimentazione con diversi modelli, funzioni di costo e parametri al fine di trovare la combinazione ottimale che migliori le prestazioni del modello.
È importante trovare un equilibrio tra un modello che sia abbastanza complesso da catturare le relazioni nei dati, ma non così complesso da soffrire di overfitting, cioè da adattarsi eccessivamente ai dati di addestramento senza riuscire generalizzare bene su nuovi dati.
Il processo di model fitting comporta solitamente vari passaggi:
Selezione del modello: regressione lineare, alberi decisionali, reti neurali, e via dicendo.
Definizione delle funzioni di costo: Le funzioni di costo misurano l’errore tra le previsioni del modello e i valori veri dei dati di addestramento. Scegliere una funzione di costo appropriata dipenderà dal tipo di problema che si sta risolvendo. Ad esempio, per la regressione lineare, si può utilizzare la somma dei quadrati degli errori (SSE). Ovviamente la scelta di una funzione di costo inadeguata può portare a valutazioni fuorviate, in alcuni scenari.
Una volta selezionato il modello e definita la funzione di costo, l’obiettivo è trovare i valori dei parametri del modello che minimizzano la funzione di costo.
Addestramento del modello: Durante l’addestramento, si passano i dati di addestramento al modello e si calcolano le previsioni. Successivamente, si calcola l’errore tra le previsioni e i valori veri e si utilizza l’algoritmo di ottimizzazione per aggiornare i parametri del modello.
Valutazione del modello: Dopo l’addestramento, è importante valutare le prestazioni del modello. Ciò viene fatto utilizzando dati di test separati, che non sono stati utilizzati durante l’addestramento.
Tuning finale: Se il modello non produce prestazioni soddisfacenti, è possibile regolare i suoi iperparametri per migliorarne le prestazioni. Gli iperparametri sono parametri che non vengono appresi dal modello durante l’addestramento, ma devono essere impostati manualmente dall’utente.
Le sette fasi descritte possono essere ripetitive e non ripetute una sola volta, anzi è spesso necessario tornare più volte su alcuni punti a dispetto di altri.
Tecnica di predicting (predizione)
La predizione nel machine learning è il processo di utilizzo di un modello addestrato per fare previsioni o stime su nuovi dati non visti in precedenza. Dopo aver addestrato un modello, l’obiettivo principale della predizione è ancora una volta di utilizzare il modello per fare previsioni accurate su nuovi esempi o dati di test. La predizione nel machine learning è un processo chiave per applicazioni come la classificazione, la regressione o il riconoscimento di pattern.
Il processo di predizione comporta, in questo caso, i seguenti passaggi:
Preparazione dei dati di input: Prima di effettuare una previsione, i nuovi dati devono essere preparati in modo coerente con i dati di addestramento utilizzati per addestrare il modello. Ciò può comportare la pulizia dei dati, l’estrazione delle caratteristiche e l’applicazione delle trasformazioni necessarie.
Utilizzo del modello addestrato: Dopo aver preparato i dati di input, il modello addestrato viene utilizzato per generare previsioni. Il modello prende in input i dati di test e restituisce una previsione o un valore stimato.
Valutazione delle previsioni: Una volta effettuate le previsioni, è importante valutare l’accuratezza e le prestazioni del modello. Ciò viene fatto confrontando le previsioni con i valori di riferimento o le etichette corrette dei dati di test.
La cross-validation (validazione incrociata) è una ulteriore tecnica utilizzata nel machine learning per valutare le prestazioni di un modello utilizzando un insieme limitato di dati di addestramento. L’obiettivo della cross-validation è stimare l’accuratezza del modello su dati non visti, ancora una volta, fornendo una stima affidabile delle prestazioni del modello.
La cross-validation coinvolge i seguenti passaggi:
L’insieme di dati di addestramento viene diviso in diverse parti chiamate “fold”, con k intero (si parla a volte di k fold).
Addestramento e valutazione: Si seleziona una delle k fold come insieme di test e le restanti k-1 vengono utilizzate come set di addestramento. Il modello viene quindi addestrato e valutato utilizzando il set di test.
Il processo di addestramento e valutazione viene iterato k volte, utilizzando ogni volta una fold differente come set di test. In questo modo, ogni fold viene utilizzata una volta come set di test e k-1 volte come set di addestramento.
Valutazione delle prestazioni: Alla fine della k-fold cross-validation, si ottengono k valutazioni delle prestazioni del modello. Queste valutazioni possono essere aggregate per ottenere una stima media delle prestazioni del modello.
Tipicamente, si calcolano la media e la deviazione standard delle metriche di valutazione, come l’accuratezza o l’errore medio, per ottenere una stima affidabile delle prestazioni del modello. La cross-validation può essere utile perché permette di valutare il modello su più dati di test, fornendo una stima più affidabile delle sue prestazioni rispetto a una singola suddivisione dei dati.
Machine learning pratico con Python
Proviamo a mettere in pratica i concetti visti usando la libreria sci-kit. Proviamo una semplice regressione lineare, per cui sottoponiamo i dati di x e y in due array e proponiamo all’algoritmo di “prevedere” l’andamento del grafico per x = 100, 101 e 102.
# Importare le librerie necessarie
from sklearn.linear_model import LinearRegression
import numpy as np
# Dati di addestramento
X_train = np.array([[1], [2], [3], [4], [5]])
y_train = np.array([100, 200, 300, 400, 500])
# Creare un'istanza del modello di regressione lineare
model = LinearRegression()
# Addestrare il modello utilizzando i dati di addestramento
model.fit(X_train, y_train)
# Dati di test per la previsione
X_test = np.array([[100], [101], [102]])
# Fare la previsione utilizzando il modello addestrato
y_pred = model.predict(X_test)
# Stampare le previsioni
print("Previsioni:", y_pred)
Le previsioni saranno:
Previsioni: [10000. 10100. 10200.]
il che ricalca effettivamente l’andamento dei dati che abbiamo proposto (un incremento di 100 ad ogni passaggio da un punto all’altro, se ci fate caso).
Scikit-learn può fare molto altro, ovviamente, tanto che fornisce decine di algoritmi e modelli di apprendimento automatico integrati, che sono chiamati tecnicamente stimatori (estimators). Ognuno di essi può essere adattato ad alcuni dati utilizzando il suo metodo di adattamento.
Ecco un semplice esempio in cui adattiamo un estimatore – un algoritmo specifico, di fatto – detto RandomForestClassifier (per dettagli vedi l’articolo sugli alberi decisionali) ad alcuni dati di base:
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(random_state=0)
X = [[ 1, 2, 3], # 2 samples, 3 features
[11, 12, 13]]
y = [0, 1] # classes of each sample
clf.fit(X, y)
pred = [[ 10, 20, 30], # altri 3 samples, 3 features
[110, 120, 130],
[1100, 1200, 1300]]
print ( clf.predict(X) )
print ( clf.predict( pred ) )
Possiamo fare uso del metodo semplicemente guardando gli esempi e sfruttando la documentazione, ovviamente conoscerne il funzionamento interno sarà utile a valutazioni di fino relative al margine di errore ed al fitting dei dati. Principio è sempre lo stesso: proviamo ad addestrare il nostro algoritmo con dei dati di base e poi ci inventiamo un “cervello” artificiale che sappia decidere sulla base dei dati precedenti. Per l’appunto, apprendimento macchina.
Il pattern matching è una tecnica utilizzata in informatica per individuare e riconoscere pattern specifici all’interno di dati più grandi o complessi. Può essere implementato in vari contesti, tra cui linguaggi di programmazione, analisi di testo, elaborazione di immagini e altro ancora. In sostanza il pattern matching coinvolge la ricerca di corrispondenze tra un modello definito e un insieme di dati o di una struttura dati più ampia. Questo può essere fatto attraverso l’uso di espressioni regolari, algoritmi specifici o strutture dati che consentono di identificare e manipolare le corrispondenze.
Ad esempio, nei linguaggi di programmazione, il pattern matching può essere utilizzato per cercare un certo schema o combinazione di dati all’interno di una stringa, una lista, un array o altre strutture dati. Questa tecnica è estremamente potente poiché consente di identificare e gestire rapidamente dati complessi in base a criteri specifici.
Applicazioni del pattern matching
Il pattern matching è una tecnica fondamentale sia nell’ambito dell’intelligenza artificiale (IA) che in molti altri campi dell’informatica. Nell’ambito dell’IA, il pattern matching è utilizzato in varie applicazioni:
Elaborazione del linguaggio naturale (NLP):
Riconoscimento dell’entità nominata (NER): Identificazione di entità come nomi di persone, luoghi, date, ecc., all’interno di testi. Questo utilizza spesso algoritmi di pattern matching per riconoscere modelli predefiniti.
Analisi sintattica e semantica: Nell’analisi grammaticale o nell’interpretazione del significato di una frase, il pattern matching viene usato per rilevare strutture sintattiche o semantiche.
Motori di ricerca e indicizzazione:
Ricerca di testo: Motori di ricerca come Google utilizzano algoritmi di pattern matching avanzati per trovare corrispondenze tra la query dell’utente e le pagine web indicizzate.
Indicizzazione: Per indicizzare documenti o testi, si utilizzano spesso tecniche di pattern matching per estrarre parole chiave, concetti o strutture di dati.
Pattern Recognition: In molte applicazioni di machine learning, il riconoscimento di pattern è il cuore dell’addestramento e dell’applicazione dei modelli.
Preprocessing dei dati: Nell’analisi dei dati, l’identificazione e l’eliminazione di determinati pattern indesiderati possono migliorare la qualità dei dati utilizzati per l’addestramento dei modelli.
Sistemi di raccomandazione e personalizzazione:
Raccomandazioni personalizzate: Nei sistemi di raccomandazione, l’analisi dei pattern dei comportamenti degli utenti può guidare la personalizzazione delle raccomandazioni.
Automazione e robotica:
Visione artificiale: Nella visione artificiale e nell’elaborazione delle immagini, il pattern matching è utilizzato per rilevare oggetti, riconoscere volti, ecc.
In sostanza, il pattern matching costituisce un elemento cruciale in molte applicazioni dell’IA, consentendo di identificare e interpretare dati complessi, sia strutturati che non strutturati, per prendere decisioni intelligenti e fornire soluzioni mirate e precise.
Problema e soluzione generale del pattern matching
Dato un testo generico T composto da n caratteri ed un pattern P di m caratteri (una lettera, una parola o una stringa di lunghezza variabile), con m minore o uguale a n, vogliamo determinare tutti i match del pattern all’interno di T. Se ad esempio il testo T è dato da:
“the cat is on the table”
e il pattern P= “the”, il match dovrà restituire il punto del testo in cui è presente la corrispondenza, ovvero:
{1, 15} -> “the cat is on the table”
La strategia più immediata per fare pattern matching è naturalmente quella di posizionare P all’inizio del testo, e per ogni singolo carattere da 1 a n spostare di uno la stringa, fino ad arrivare alla posizione limite n-m+1 (ipotizziamo di lavorare con stringhe in base 1 per non complicare la notazione), e tenendo traccia in una lista inizialmente delle corrispondenze trovate.
Questo pseudocodice rappresenta un approccio “ingenuo” o basico al problema del pattern matching, che esamina tutte le possibili posizioni nel testo T confrontando il pattern P.
In pseudo codice:
Funzione patternMatching(testo T, pattern P)
n = lunghezza di T
m = lunghezza di P
corrispondenze = lista vuota
per ogni i da 1 a n - m + 1
trovatoMatch = vero
per ogni j da 1 a m
se T[i + j - 1] non corrisponde a P[j]
trovatoMatch = falso
interrompi il ciclo
se trovatoMatch è vero
aggiungi (i, i + m - 1) a corrispondenze
restituisci corrispondenze
Fine Funzione
Approcci più efficenti al pattern matching
Tuttavia, esistono approcci più efficienti come l’algoritmo di Knuth-Morris-Pratt (KMP) o l’algoritmo di Rabin-Karp che sono in grado di gestire questa ricerca in modo più ottimizzato, specialmente con testi di grandi dimensioni. L’algoritmo di Rabin-Karp e l’algoritmo di Knuth-Morris-Pratt (KMP) sono entrambi utilizzati per la ricerca di pattern, ma si differenziano principalmente nel loro approccio e nella logica di esecuzione. Entrambi hanno complessità O(n+m).
1. Principio di funzionamento:
Rabin-Karp: Si basa sull’hashing per confrontare gli hash del pattern con gli hash delle sottostringhe del testo. Una volta che gli hash coincidono, esegue un controllo dettagliato per confermare la corrispondenza.
KMP: Sfrutta informazioni precalcolate sul pattern stesso (il Longest Proper Prefix which is also Suffix – LPS) per ottimizzare la ricerca nel testo. L’utilizzo della lista LPS consente di evitare confronti inutili tra il pattern e il testo, saltando direttamente alle posizioni potenzialmente interessanti nel testo.
2. Efficienza:
Rabin-Karp: Ha una complessità media di tempo di O(n + m) nell’identificare tutte le corrispondenze, ma richiede un’adeguata gestione delle collisioni hash.
KMP: Ha una complessità temporale di O(n + m) nel trovare tutte le occorrenze del pattern nel testo, senza dipendere da fattori come la funzione di hash. È particolarmente efficiente per testi di grandi dimensioni grazie alla sua logica di utilizzo delle informazioni precalcolate sul pattern.
3. Approccio alla ricerca:
Rabin-Karp: Utilizza l’hashing per identificare le possibili corrispondenze tra il pattern e le sottostringhe del testo.
KMP: Sfrutta le informazioni precalcolate (LPS) per evitare di ricontrollare caratteri che già corrispondono, consentendo di saltare parti del testo dove è già stata eseguita una corrispondenza parziale.
In sintesi, Rabin-Karp si basa sull’hashing per cercare le corrispondenze, mentre KMP utilizza informazioni precalcolate sul pattern per ottimizzare la ricerca. Entrambi sono efficienti, ma la scelta tra i due dipende dalle specifiche esigenze del problema e dalle caratteristiche del testo e del pattern su cui si sta lavorando.
algoritmo di Knuth-Morris-Pratt
Questo pseudocodice implementa l’algoritmo di Knuth-Morris-Pratt (KMP) per la ricerca efficiente di un pattern all’interno di un testo. Utilizza una lista lps (Longest Proper Prefix which is also Suffix) per memorizzare le informazioni sul pattern per ottimizzare la ricerca nel testo senza ricomparare confronti inutili. L’algoritmo KMP riduce il numero di confronti necessari confrontando il pattern P direttamente con il testo T solo quando c’è una probabile corrispondenza.
Funzione calcolaLPS(pattern P, lunghezza m, lista lps)
lunghezzaPrefisso = 0
lps[1] = 0
i = 2
while i <= m
if P[i] è uguale a P[lunghezzaPrefisso + 1]
lunghezzaPrefisso = lunghezzaPrefisso + 1
lps[i] = lunghezzaPrefisso
i = i + 1
else
if lunghezzaPrefisso non è uguale a 0
lunghezzaPrefisso = lps[lunghezzaPrefisso]
else
lps[i] = 0
i = i + 1
Funzione KMP(testo T, pattern P)
n = lunghezza di T
m = lunghezza di P
lps = lista di lunghezza m+1
corrispondenze = lista vuota
calcolaLPS(P, m, lps)
i = 1
j = 1
while i <= n
if T[i] è uguale a P[j]
i = i + 1
j = j + 1
if j è uguale a m
aggiungi (i - j, i - 1) a corrispondenze
j = lps[j]
else
if j non è uguale a 1
j = lps[j]
else
i = i + 1
restituisci corrispondenze
Fine Funzione
algoritmo di Rabin-Karp
L’algoritmo di Rabin-Karp è una tecnica di ricerca di pattern che sfrutta l’hashing per trovare corrispondenze tra un pattern P e un testo T. Si basa sull’uso di funzioni di hash per ridurre il tempo di ricerca.
Ecco una spiegazione di alto livello del funzionamento di Rabin-Karp:
Hashing del pattern e delle sottostringhe del testo:
Calcoliamo l’hash del pattern P.
Calcoliamo l’hash delle prime m caratteri del testo T, dove m è la lunghezza del pattern. Questo ci fornisce un hash iniziale per confrontarlo con l’hash del pattern.
Confronto degli hash:
Se gli hash corrispondono, eseguiamo un controllo esaustivo carattere per carattere tra il pattern e la sottostringa del testo per confermare la corrispondenza.
Se gli hash non corrispondono, passiamo alla successiva sottostringa del testo, calcoliamo il suo hash e confrontiamo di nuovo con l’hash del pattern.
Riduzione del numero di confronti:
Utilizzando il concetto di rolling hash, ovvero aggiornando l’hash della sottostringa successiva in modo efficiente, possiamo ridurre il numero di confronti diretti tra il pattern e le sottostringhe del testo.
Quando gli hash delle sottostringhe coincidono con l’hash del pattern, effettuiamo una verifica carattere per carattere per confermare la corrispondenza.
Gestione delle collisioni hash:
Poiché gli hash potrebbero collidere anche se i corrispondenti sottostringhe non sono effettivamente uguali, è necessario eseguire una verifica dettagliata solo quando gli hash coincidono.
L’algoritmo di Rabin-Karp può essere più efficiente in alcuni casi rispetto all’approccio ingenuo di confronto di stringhe in quanto sfrutta gli hash per evitare confronti inutili tra il pattern e il testo. Tuttavia, richiede un’adeguata gestione delle collisioni hash e può essere influenzato dalle scelte di progettazione della funzione di hash.
Funzione calcolaHash(stringa s, lunghezza m)
hash = 0
per ogni carattere in s[1:m]
hash = hash * primoNumeroPrimo + valoreAscii(carattere)
restituisci hash
Fine Funzione
Funzione RabinKarp(testo T, pattern P)
n = lunghezza di T
m = lunghezza di P
primoNumeroPrimo = un numero primo arbitrario
hashPattern = calcolaHash(P, m)
hashTesto = calcolaHash(T, m)
per ogni i da 1 a n - m + 1
se hashPattern è uguale a hashTesto
se T[i:i+m-1] è uguale a P
stampa "Match trovato a indice", i
se i < n - m + 1
hashTesto = (hashTesto - valoreAscii(T[i]) * (primoNumeroPrimo^(m-1))) * primoNumeroPrimo + valoreAscii(T[i+m])
Fine Funzione
Pattern matching in Java
String testo = "Il gatto è sulla sedia";
String pattern = "gatto";
boolean match = testo.contains(pattern);
if (match) {
System.out.println("Pattern trovato!");
} else {
System.out.println("Pattern non trovato.");
}
Pattern matching in C++
#include <iostream>
#include <string>
using namespace std;
int main() {
string testo = "Il gatto è sulla sedia";
string pattern = "gatto";
if (testo.find(pattern) != string::npos) {
cout << "Pattern trovato!" << endl;
} else {
cout << "Pattern non trovato." << endl;
}
return 0;
}
Pattern matching in PHP
$testo = "Il gatto è sulla sedia";
$pattern = "gatto";
if (strpos($testo, $pattern) !== false) {
echo "Pattern trovato!";
} else {
echo "Pattern non trovato.";
}
$testo = "Il gatto è sulla sedia";
$pattern = "/gatto/";
if (preg_match($pattern, $testo)) {
echo "Pattern trovato!";
} else {
echo "Pattern non trovato.";
}
Pattern matching in Python
testo = "Il gatto è sulla sedia"
pattern = "gatto"
if pattern in testo:
print("Pattern trovato!")
else:
print("Pattern non trovato.")
FizzBuzz è un popolare gioco matematico spesso usato come esercizio per insegnare ai bambini i concetti di divisione e multipli. Questo gioco può essere utilizzato sia come strumento didattico per insegnare i concetti di divisione ai bambini, sia come esercizio di programmazione per valutare le abilità di programmazione di base.
L’obiettivo è generare una sequenza di numeri da 1 a N, sostituendo determinati numeri con parole specifiche in base a determinate regole. Per ogni numero nella sequenza, si applicano le seguenti regole:
Se il numero è divisibile sia per 3 che per 5, anziché stampare il numero, si stampa “FizzBuzz“.
Se il numero è solo divisibile per 3, si stampa “Fizz”.
Se il numero è solo divisibile per 5, si stampa “Buzz”.
Se il numero non è divisibile né per 3 né per 5, si stampa semplicemente il numero stesso.
L’obiettivo è creare una sequenza di numeri in cui i multipli di 3 vengono sostituiti da “Fizz”, i multipli di 5 vengono sostituiti da “Buzz”, e i multipli di entrambi 3 e 5 vengono sostituiti da “FizzBuzz”. Il problema FizzBuzz è un esercizio di programmazione molto popolare, spesso utilizzato nei colloqui di lavoro per valutare la comprensione delle strutture di controllo e della logica condizionale.
Nonostante la sua apparente semplicità, ci sono diversi errori comuni che i programmatori possono commettere nella sua implementazione:
Ordine errato delle condizioni: Verificare prima la divisibilità per 3 o per 5 anziché per entrambi. Questo può portare a non stampare mai “FizzBuzz” per i numeri divisibili sia per 3 che per 5, poiché le condizioni precedenti catturano già questi numeri. È importante controllare prima la condizione più specifica (divisibilità per 3 e 5) e poi quelle più generali. mautoblog.com
Mancata gestione dei numeri non divisibili: Dimenticare di stampare il numero stesso quando non è divisibile né per 3 né per 5. Ogni numero che non soddisfa le condizioni per “Fizz”, “Buzz” o “FizzBuzz” dovrebbe essere stampato come numero stesso. Medium+13mautoblog.com+13codenewbie.org+13
Uso improprio dell’operatore confronto/assegnamento: Non utilizzare correttamente l’operatore modulo (%) per determinare la divisibilità. Ad esempio, usare i % 3 = 0 invece di i % 3 == 0 può causare errori di sintassi o logici nel codice.
Inizializzazione o range errato del ciclo: Iniziare il ciclo da 0 invece che da 1, o terminare prima di raggiungere il numero desiderato. Ad esempio, un ciclo che va da 0 a 99 invece che da 1 a 100 non rispetta le specifiche del problema.
Errori di stampa o formattazione: Stampare “Fizzbuzz” invece di “FizzBuzz” o includere spazi o caratteri non necessari può portare a risultati non conformi alle aspettative. blog.regehr.org
Mancata comprensione delle specifiche: Interpretare erroneamente le regole del problema, come scambiare l’associazione tra “Fizz” e “Buzz” con i numeri 3 e 5, rispettivamente. Reddit
Evitando questi errori comuni, è possibile implementare una soluzione FizzBuzz corretta ed efficiente.
Dispensa in PDF: Re-Code
Come imparare velocemente a programmare in C++, con una semplice guida progressiva passo-passo.
#include <iostream>
using namespace std;
void fizzbuzz(int n) {
for (int i = 1; i <= n; ++i) {
if (i % 3 == 0 && i % 5 == 0) {
cout << "FizzBuzz" << endl;
} else if (i % 3 == 0) {
cout << "Fizz" << endl;
} else if (i % 5 == 0) {
cout << "Buzz" << endl;
} else {
cout << i << endl;
}
}
}
int main() {
int n = 20; // Puoi cambiare questo numero per visualizzare la sequenza fino a un limite diverso
fizzbuzz(n);
return 0;
}
Una delle migliori codifiche del problema prevede che vengano utilizzate solo tre righe di codice, sfruttando le condizioni implicite innestate, che in C++ diventano come segue.
# include < iostream >
using namespace std ;
int main () {
for ( int i = 1; i <= 100; i ++)
cout << ( i % 3 == 0 ? " Fizz " : " " ) << ( i % 5
== 0 ? " Buzz " : " " ) << ( i % 3 && i % 5 ?
to_string ( i ) : " " ) << endl ;
return 0;
}
Fizz Buzz in JS
Altre versioni corrette, più standard, sono queste (fonte).
// JavaScript program for Fizz Buzz Problem
// by checking every integer individually
function fizzBuzz(n) {
let res = [];
for (let i = 1; i <= n; ++i) {
// Check if i is divisible by both 3 and 5
if (i % 3 === 0 && i % 5 === 0) {
// Add "FizzBuzz" to the result array
res.push("FizzBuzz");
}
// Check if i is divisible by 3
else if (i % 3 === 0) {
// Add "Fizz" to the result array
res.push("Fizz");
}
// Check if i is divisible by 5
else if (i % 5 === 0) {
// Add "Buzz" to the result array
res.push("Buzz");
}
else {
// Add the current number as a string to the
// result array
res.push(i.toString());
}
}
return res;
}
// Driver code
let n = 20;
let res = fizzBuzz(n);
console.log(res.join(' '));
Fizz Buzz in Python
Procedendo per gradi, un programmatore principiante potrebbe essere tentato dallo scrivere qualcosa del genere, considerando che i casi in gioco sono soltanto tre per cui servono tre condizioni per tutti i numeri che vanno da 1 ad N:
def fizzbuzz(n):
# Iniziamo un ciclo che va da 1 fino a n (incluso)
for i in range(1, n+1):
# Se i è divisibile per 3, stampiamo "Fizz"
if i % 3 == 0:
print("Fizz")
# Altrimenti, se i è divisibile per 5, stampiamo "Buzz"
elif i % 5 == 0:
print("Buzz")
# Altrimenti, se non è divisibile né per 3 né per 5, stampiamo "FizzBuzz"
else:
print("FizzBuzz")
# Assegniamo un valore di esempio a n e chiamiamo la funzione fizzbuzz con questo valore
n = 10
fizzbuzz(n)
A leggerla così potrebbe sembrare corretto, ma basta lanciare il programma per rendersi conto che non tira fuori quello che servirebbe. La sequenza risultante infatti è solo parzialmente corretta:
Per fare questo, ci rendiamo conto che i casi da considerare sono in realtà 4:
Se un numero è divisibile solo per 3, viene sostituito con “Fizz”.
Se un numero è divisibile solo per 5, viene sostituito con “Buzz”.
Se un numero è divisibile sia per 3 che per 5, viene sostituito con “FizzBuzz”.
Se un numero non è divisibile né per 3 né per 5, rimane invariato e viene semplicemente stampato.
Chiarito questo, scriviamo:
# Definiamo una funzione chiamata fizzbuzz che prende un parametro n
def fizzbuzz(n):
# Iniziamo un ciclo che va da 1 fino a n (incluso)
for i in range(1, n+1):
# Se i è divisibile per 3, stampiamo "Fizz"
if i % 3 == 0:
print("Fizz")
# Altrimenti, se i è divisibile per 5, stampiamo "Buzz"
elif i % 5 == 0:
print("Buzz")
# Altrimenti, se non è divisibile né per 3 né per 5, stampiamo "FizzBuzz"
else:
print("FizzBuzz")
# Assegniamo un valore di esempio a n e chiamiamo la funzione fizzbuzz con questo valore
n = 10
fizzbuzz(n)
Ordinare letteralmente a caso: guida pratica al bogosort
Lo chiamano bogosort per non chiamarlo stupid sort, ordinamento stupido, il che potrebbe suonare grottesco o aggressivo agli occhi di qualche studente. In effetti il Bogosort è un algoritmo di ordinamento molto inefficiente e non pratico, tanto che ci si chiede a cosa possa servire nella pratica. Funziona seguendo un metodo casuale: consiste nel mescolare casualmente l’intera lista e verificare, ad ogni tentativo, se è ordinata. Se la lista non è ordinata, il processo di mescolamento casuale viene ripetuto fino a quando la lista è ordinata.
Ordinare a caso, fino a quando (forse)è ordinato
Hai mai desiderato un algoritmo che incarnasse l’entropia dell’universo? Ti presentiamo il Bogosort: l’algoritmo che dice “E se provassimo a mischiare tutto finché per miracolo è ordinato?”
Lo studio del Bogosort, sebbene sia un algoritmo di ordinamento inefficace e impraticabile, può essere utile per diversi motivi. Non sembrerebbe, a prima vista. A che cosa dovrebbe servire “ordinare a caso”, in effetti? Ad esempio può essere un esercizio didattico utile per capire meglio i concetti di base degli algoritmi di ordinamento, anche se in pratica non è utilizzato in applicazioni reali a causa della sua estrema inefficienza. Serve anche a:
Comprendere i limiti degli algoritmi: Studiare il Bogosort aiuta a capire meglio cosa rende un algoritmo efficiente o inefficiente. È un esempio estremo di un algoritmo molto inefficiente e fornisce un confronto con algoritmi di ordinamento efficienti come Quicksort o Mergesort.
Approfondire la comprensione dei criteri di confronto: L’analisi del Bogosort può approfondire la comprensione dei criteri utilizzati per valutare le prestazioni degli algoritmi di ordinamento, come il tempo di esecuzione, la complessità computazionale e l’efficienza.
Apprendere i concetti di casualità / probabilità: Il Bogosort utilizza il concetto di casualità per mescolare gli elementi. Studiarlo può aiutare a comprendere meglio i concetti di casualità e probabilità nell’informatica e nei processi decisionali.
Finalità educative / divertimento: In un contesto educativo o ludico, l’apprendimento del Bogosort può essere utilizzato come esercizio per esplorare gli algoritmi e comprendere le differenze tra un approccio efficiente e uno inefficace.
Come funziona il bogosort
In altri termini, l’algoritmo Bogosort funziona in questo modo:
Mescola casualmente l’intera lista.
Verifica se la lista è ordinata.
Se la lista non è ordinata, ripete il mescolamento casuale.
Continua a ripetere il processo finché la lista non è ordinata.
Se preferisci:
Prendi una lista di numeri o di elementi ordinabili (due elementi sono ordinabili se esiste un criterio per cui uno è maggiore dell’altro).
Controlla se è ordinata. Lo è?
Se non lo è, mischiala a caso.
Ripeti dal punto 2, finché il cosmo si allinea l’algoritmo ha finito l’ordinamento per puro caso.
Si tratta di un algoritmo interessante perchè l’uso di un rimescolamento casuale introduce non determinismo e questo, naturalmente, cambia in modo radicale l’approccio algoritmico: che è deterministico quando stabiliamo che la somma di 2+2 è 4, comunque decidiamo di calcolarlo, e diventa non deterministico se introduciamo un evento non prevedibile come il rimescolamento casuale degli elementi.
Cosa che, alla prova dei fatti, è difficile anche da prevedere come esito, poichè la probabilità di ordinare N elementi casualmente è ben più alta del numero di combinazioni casuali ottenibili. Che sono N! (N fattoriale), per inciso: per cui se hai 3 elementi distinti (1, 2, 3), i possibili ordini distinti sono 3!=3×2×1=6 in tutto, ovvero:
123
132
213
231
312
321
Se hai, ad esempio, 4 elementi distinti, i possibili ordini distinti sono 4!=4×3×2×1=244!=4×3×2×1=24 ordini distinti. In un caso solo 1 combinazione su 6 sarà corretta (24% di probabilità di ordinare al primo colpo), nel caso di N=4 avremo 1 su 24 probabilità di trovare la combinazione ordinata (4% circa).
Poiché il mescolamento casuale è completamente non deterministico, nel bogosort, non c’è alcuna garanzia che l’ordinamento avverrà in un tempo ragionevole. La complessità temporale dell’algoritmo bogosort è estremamente alta, può arrivare ad essere O(N!) e può richiedere un tempo indefinito, nella pratica, per ordinare la lista non ordinata.
Bogosort in C++
Ecco un esempio di come si potrebbe implementare il Bogosort in C++
#include <iostream>
#include <algorithm>
#include <random>
// Funzione per verificare se la lista è ordinata
bool isSorted(int arr[], int size) {
for (int i = 1; i < size; ++i) {
if (arr[i - 1] > arr[i]) {
return false;
}
}
return true;
}
// Funzione per mescolare casualmente la lista
void shuffle(int arr[], int size) {
std::random_device rd;
std::mt19937 g(rd());
std::shuffle(arr, arr + size, g);
}
// Implementazione dell'algoritmo Bogosort
void bogoSort(int arr[], int size) {
while (!isSorted(arr, size)) {
shuffle(arr, size);
}
}
// Funzione di stampa della lista
void printArray(int arr[], int size) {
for (int i = 0; i < size; ++i) {
std::cout << arr[i] << " ";
}
std::cout << std::endl;
}
int main() {
int arr[] = {3, 1, 4, 5, 2}; // Lista da ordinare
int size = sizeof(arr) / sizeof(arr[0]);
std::cout << "Lista non ordinata: ";
printArray(arr, size);
// Ordina la lista utilizzando Bogosort
bogoSort(arr, size);
std::cout << "Lista ordinata: ";
printArray(arr, size);
return 0;
}
La funzione shuffle utilizza le funzioni fornite dalla libreria standard di C++ ( e ) per eseguire il mescolamento casuale dell’array. In breve tale funzione prende un array di numeri e li mescola casualmente utilizzando un generatore di numeri casuali, modificando così l’ordine originale.
Ecco cosa fa esattamente:
std::random_device rd; crea un oggetto random_device che serve come seme per il generatore di numeri casuali. Questo aiuta a generare numeri casuali veri e propri.
std::mt19937 g(rd()); crea un generatore di numeri casuali mt19937 (Mersenne twister) utilizzando rd() come seme. mt19937 è un motore di generazione di numeri casuali di alta qualità, usato molto spesso nella pratica (e anche, ad esempio, per generare numeri casuali in Excel).
std::shuffle(arr, arr + size, g); utilizza la funzione shuffle della libreria standard di C++ (che ha 4 argomenti, da non confondersi coi 3 della funzione creata). Prende l’array arr e il suo numero di elementi size e utilizza il generatore di numeri casuali g per mescolare gli elementi dell’array in modo casuale.
La copia di file in Python è un’operazione comune e, fortunatamente, il linguaggio offre strumenti robusti e versatili per gestirla. In questa guida tecnica, esploreremo i vari approcci per eseguire un’operazione di python copy file, partendo dalla copia di singoli file fino ad arrivare a scenari più complessi come la copia ricorsiva di directory.
Modulo shutil: La Scelta Professionale per la Copia di File e Directory
Quando si tratta di operazioni su file e directory di alto livello, il modulo shutil (shell utilities) è il tuo migliore amico. Offre funzioni che semplificano notevolmente compiti che, altrimenti, richiederebbero molto più codice.
1. Copia di un Singolo File: shutil.copy()
La funzione shutil.copy(src, dst) è l’opzione più semplice e comune per copiare un file. Copia il contenuto del file sorgente (src) nel file o directory di destinazione (dst).
src: Il percorso del file sorgente da copiare.
dst: Il percorso della destinazione. Può essere un file (il nome del nuovo file) o una directory (in tal caso, il file verrà copiato al suo interno mantenendo il nome originale).
Caratteristiche:
Copia i permessi del file sorgente.
Non copia i metadati come l’ora dell’ultima modifica (usa shutil.copy2() per questo).
Se dst è una directory, il file verrà copiato al suo interno con lo stesso nome.
Se dst esiste ed è un file, verrà sovrascritto. Se è una directory, il file sorgente verrà copiato al suo interno.
Esempio Pratico: Copia un file da una posizione all’altra.
Python
import shutil
import os
# Creiamo un file di testwithopen("sorgente.txt", "w") as f:
f.write("Questo è il contenuto del file sorgente.")
# 1. Copia il file sorgente in un nuovo filetry:
shutil.copy("sorgente.txt", "destinazione.txt")
print("File 'sorgente.txt' copiato in 'destinazione.txt'")
except Exception as e:
print(f"Errore durante la copia del file: {e}")
# 2. Creiamo una directory di destinazione
os.makedirs("cartella_destinazione", exist_ok=True)
# 3. Copia il file sorgente nella directory di destinazionetry:
shutil.copy("sorgente.txt", "cartella_destinazione/")
print("File 'sorgente.txt' copiato in 'cartella_destinazione/'")
except Exception as e:
print(f"Errore durante la copia del file nella cartella: {e}")
# Pulizia
os.remove("sorgente.txt")
os.remove("destinazione.txt")
os.remove("cartella_destinazione/sorgente.txt")
os.rmdir("cartella_destinazione")
2. Copia di un Singolo File con Metadati: shutil.copy2()
La funzione shutil.copy2(src, dst) è identica a shutil.copy() ma con un’aggiunta fondamentale: copia anche i metadati del file, inclusa l’ora dell’ultima modifica, l’ora di accesso e i flag.
Esempio Pratico: Dimostrare la copia dei metadati.
Python
import shutil
import os
import time
# Creiamo un file di test e modifichiamolo per avere un timestamp significativowithopen("sorgente_meta.txt", "w") as f:
f.write("Contenuto per test metadati.")
time.sleep(1) # Aspetta un secondo per avere un timestamp diverso da creazione
os.utime("sorgente_meta.txt", (time.time(), time.time())) # Aggiorna ora di accesso e modifica# Ottieni l'ora di modifica originale
original_mtime = os.path.getmtime("sorgente_meta.txt")
print(f"Ora di modifica originale: {time.ctime(original_mtime)}")
# Copia con shutil.copy()
shutil.copy("sorgente_meta.txt", "destinazione_copy.txt")
copy_mtime = os.path.getmtime("destinazione_copy.txt")
print(f"Ora di modifica con copy(): {time.ctime(copy_mtime)}")
print(f"I metadati sono gli stessi con copy(): {original_mtime == copy_mtime}\n")
# Copia con shutil.copy2()
shutil.copy2("sorgente_meta.txt", "destinazione_copy2.txt")
copy2_mtime = os.path.getmtime("destinazione_copy2.txt")
print(f"Ora di modifica con copy2(): {time.ctime(copy2_mtime)}")
print(f"I metadati sono gli stessi con copy2(): {original_mtime == copy2_mtime}")
# Pulizia
os.remove("sorgente_meta.txt")
os.remove("destinazione_copy.txt")
os.remove("destinazione_copy2.txt")
Come si può notare dall’output, shutil.copy() crea un nuovo file con un timestamp di modifica “fresco”, mentre shutil.copy2() conserva quello del file sorgente.
3. Copia Ricorsiva di Directory: shutil.copytree()
Questa è la funzione per eccellenza quando hai bisogno di copiare un’intera struttura di directory, inclusi tutti i suoi file e sottodirectory.
dst: La directory di destinazione. Non deve esistere prima di chiamare copytree. Se esiste, verrà generato un errore.
dirs_exist_ok=False (default): Se True, la directory di destinazione può esistere, e i contenuti saranno uniti (ma i file esistenti saranno sovrascritti). Attenzione: Questa opzione è stata aggiunta in Python 3.8. Per versioni precedenti, devi gestire l’esistenza della directory manualmente.
ignore (opzionale): Una funzione richiamabile che permette di escludere file o directory dalla copia (simile a .gitignore).
Esempio Pratico: Copiare una struttura di cartelle completa.
Python
import shutil
import os
# Creiamo una struttura di directory di test
os.makedirs("sorgente_dir/sottocartella", exist_ok=True)
withopen("sorgente_dir/file1.txt", "w") as f:
f.write("File 1")
withopen("sorgente_dir/sottocartella/file2.txt", "w") as f:
f.write("File 2")
# Copia ricorsiva della directorytry:
# Se 'destinazione_dir' esiste, la rimuoiviamo prima per evitare errori nelle versioni < 3.8if os.path.exists("destinazione_dir"):
shutil.rmtree("destinazione_dir")
shutil.copytree("sorgente_dir", "destinazione_dir")
print("Directory 'sorgente_dir' copiata ricorsivamente in 'destinazione_dir'")
# Verifichiamo il contenuto (opzionale)
print("Contenuto di 'destinazione_dir':")
for root, dirs, files in os.walk("destinazione_dir"):
level = root.replace("destinazione_dir", '').count(os.sep)
indent = ' ' * 4 * (level)
print(f'{indent}{os.path.basename(root)}/')
subindent = ' ' * 4 * (level + 1)
for f in files:
print(f'{subindent}{f}')
except Exception as e:
print(f"Errore durante la copia ricorsiva: {e}")
# Pulizia
shutil.rmtree("sorgente_dir")
shutil.rmtree("destinazione_dir")
Copia Ricorsiva con Esclusione di File/Directory:
Supponiamo di voler copiare una directory ma escludere tutti i file .log e una sottocartella specifica.
Python
import shutil
import os
# Creiamo una struttura di directory più complessa
os.makedirs("progetto_sorgente/data", exist_ok=True)
os.makedirs("progetto_sorgente/logs", exist_ok=True) # Questa cartella verrà esclusawithopen("progetto_sorgente/config.ini", "w") as f: f.write("config")
withopen("progetto_sorgente/data/user.csv", "w") as f: f.write("data")
withopen("progetto_sorgente/logs/app.log", "w") as f: f.write("log data")
withopen("progetto_sorgente/temp.log", "w") as f: f.write("temp log")
defignore_patterns(path, names):
ignored = []
# Escludi tutti i file .logfor name in names:
if name.endswith('.log'):
ignored.append(name)
# Escludi la directory 'logs'if'logs'in names:
ignored.append('logs')
print(f"Ignoro in {path}: {ignored}")
return ignored
try:
if os.path.exists("progetto_destinazione"):
shutil.rmtree("progetto_destinazione")
shutil.copytree("progetto_sorgente", "progetto_destinazione", ignore=ignore_patterns)
print("\nCopia ricorsiva con pattern di esclusione completata.")
print("\nContenuto della destinazione (dovrebbe mancare 'logs/' e i file .log):")
for root, dirs, files in os.walk("progetto_destinazione"):
level = root.replace("progetto_destinazione", '').count(os.sep)
indent = ' ' * 4 * (level)
print(f'{indent}{os.path.basename(root)}/')
subindent = ' ' * 4 * (level + 1)
for f in files:
print(f'{subindent}{f}')
except Exception as e:
print(f"Errore durante la copia con esclusione: {e}")
# Pulizia
shutil.rmtree("progetto_sorgente")
if os.path.exists("progetto_destinazione"):
shutil.rmtree("progetto_destinazione")
4. Copia a Basso Livello: open() e Lettura/Scrittura
Per scenari molto specifici, o se si vuole un controllo granulare sul processo di copia, è possibile copiare il file leggendo il contenuto in blocchi e scrivendolo. Questo è ciò che le funzioni di shutil fanno “sotto il cofano”.
Questo approccio è utile per:
Copiare file molto grandi per evitare di caricare l’intero contenuto in memoria.
Implementare logica di copia personalizzata (es. visualizzare una barra di progresso, crittografare durante la copia).
Esempio Pratico: Copia un file in blocchi.
Python
import os
defcopy_file_manual(src_path, dst_path, buffer_size=4096):"""
Copia un file leggendolo e scrivendolo in blocchi.
"""try:
withopen(src_path, 'rb') as fsrc: # 'rb' per lettura in modalità binariawithopen(dst_path, 'wb') as fdst: # 'wb' per scrittura in modalità binariawhileTrue:
buffer = fsrc.read(buffer_size)
ifnot buffer:
break
fdst.write(buffer)
print(f"File '{src_path}' copiato manualmente in '{dst_path}'")
except FileNotFoundError:
print(f"Errore: Il file sorgente '{src_path}' non trovato.")
except Exception as e:
print(f"Errore durante la copia manuale del file: {e}")
# Creiamo un file di test più grandewithopen("large_sorgente.bin", "wb") as f:
f.write(os.urandom(1024 * 1024 * 5)) # 5 MB di dati casuali
copy_file_manual("large_sorgente.bin", "large_destinazione.bin")
# Pulizia
os.remove("large_sorgente.bin")
os.remove("large_destinazione.bin")
L’uso della modalità binaria ('rb', 'wb') è cruciale per garantire che tutti i byte del file vengano copiati correttamente, specialmente per file non testuali (immagini, video, eseguibili).
Considerazioni Finali sul “Python Copy File”
Gestione degli Errori: In tutti gli esempi, è fondamentale includere blocchi try-except per gestire potenziali IOError (es. permessi negati, disco pieno, file non trovato) o altre eccezioni.
Sovrascrittura:shutil.copy() e shutil.copy2() sovrascrivono i file di destinazione se esistono. shutil.copytree() genera un errore se la directory di destinazione esiste (a meno che non si usi dirs_exist_ok=True in Python 3.8+).
Simbolici Link:shutil.copy() e shutil.copy2() copiano il contenuto di un link simbolico, non il link stesso. Per copiare il link come link, si può usare shutil.copy(src, dst, follow_symlinks=False).
Sicurezza: Fai attenzione quando copi file da fonti non fidate, specialmente in posizioni sensibili del sistema, poiché potresti inavvertitamente sovrascrivere file importanti.
In generale, per la maggior parte delle esigenze di python copy file, le funzioni del modulo shutil sono la scelta consigliata per la loro semplicità, efficienza e gestione integrata di molti dettagli che altrimenti dovrebbero essere gestiti manualmente.
Le matrici in C++ sono strutture dati che rappresentano un insieme bidimensionale di elementi organizzati in righe e colonne. Sono utilizzate per memorizzare e manipolare dati in un formato tabellare.
Ecco una guida introduttiva completa sulle matrici in C++, che potete sfruttare per il vostro codice e per adattarlo a varie situazioni.
Definizione di una Matrice
Array Multidimensionale
Una matrice viene definita come un array a due dimensioni (con massima generalità, almeno due). In questo caso definiamo due costanti, una per il numero di righe (ROWS) ed una per il numero di colonne (COLS), poi andiamo a definite la matrice che sarà di dimensioni 3×3, conterrà 3×3=9 elementi e sarà composta da interi e di forma quadrata.
constint ROWS = 3; constint COLS = 3; int matrix[ROWS][COLS]; // Matrice 3x3 di interi
Matrice Inizializzata
Se volessi inizializzare la matrice con numeri, andrei a metterli tra parentesi graffe come indicato di seguito.
int matrix[3][3] =
{
{1, 2, 3},
{4, 5, 6},
{7, 8, 9}
}; // Matrice 3x3 inizializzata
Accesso agli Elementi
int value = matrix[1][2]; // Accesso all'elemento in posizione (1, 2)
Per mostrare i valori della matrice, li stampiamo dentro un ciclo for.
for (int i = 0; i < ROWS; ++i) { for (int j = 0; j < COLS; ++j) {
cout << matrix[i][j] << " "; // Stampa degli elementi
}
cout << std::endl; // mette una nuova riga per ogni riga della matrice
}
Operazioni Avanzate
Manipolazione: Esegui operazioni come somma, sottrazione, moltiplicazione tra matrici.
Transposizione: Scambia righe e colonne di una matrice.
Determinante: Calcola il determinante di una matrice quadrata.
Inversione: Trova l’inversa di una matrice quadrata.
Librerie Utili
iostream: Per l’input/output.
cmath: Per operazioni matematiche (es. calcolo della radice quadrata).
vector: Per rappresentare matrici dinamiche.
Considerazioni Importanti:
Le matrici in C++ sono rappresentate come array multidimensionali, quindi le operazioni dirette di manipolazione possono risultare complesse.
Per operazioni avanzate, considera l’uso di librerie esterne come Eigen per algebra lineare.
Le matrici sono una risorsa potente e versatile nella programmazione, utilizzate in matematica, grafica, elaborazione delle immagini, calcolo scientifico e molto altro ancora. Pratica con operazioni di base e gradualmente esplora operazioni più avanzate per sfruttare appieno il loro potenziale.
Esercizio: rilevare solo gli elementi diagonale principale
Per trovare gli elementi della diagonale secondaria di una matrice 3×3 in C++, puoi usare un ciclo for per scorrere gli elementi in modo tale che la somma degli indici di riga e colonna sia uguale a 2 (considerando che gli indici partono da 0).
Ecco un esempio di come puoi farlo:
#include <iostream>
using namespace std;
int main() {
int matrix[3][3] =
{{1, 2, 3},
{4, 5, 6},
{7, 8, 9}};
cout << "Elementi della diagonale principale:" << std::endl;
for (int i = 0; i < 3; ++i) {
cout << matrix[i][i] << " ";
}
cout << endl;
return 0;
}
Elementi diagonale secondaria
In questo esempio, il ciclo for scorre gli elementi della diagonale secondaria utilizzando l’indice i e calcolando l’indice della colonna come 2 - i. Questo approccio si basa sul fatto che la somma degli indici di riga e colonna per gli elementi della diagonale secondaria è costante e uguale a 2 nella matrice 3×3.
Se i = 0, infatti 2-i = 2-0 = 2; se i = 1, 2-i = 2-1 = 1; Se i = 2, inifine, 2-i = 2-2 = 0.
#include <iostream>
using namespace std;
int main() {
int matrix[3][3] =
{{1, 2, 3},
{4, 5, 6},
{7, 8, 9}};
cout << "Elementi della diagonale secondaria:" << endl;
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
if ( (i+j) == 2 ) //allora siamo sulla diagonale secondaria
cout << matrix[i][j] << " ";
}
cout << endl;
return 0;
}
Elementi con somma di indici pari (Scacchiera, un elemento sì e uno no)
Questo codice adatta l’approccio precedente per considerare solo le posizioni con una somma di indici pari.
La condizione (i + (k - i)) % 2 == 0 verifica se la somma degli indici è pari prima di estrarre e stampare l’elemento corrispondente.
Puoi utilizzare questa logica per estrarre solo gli elementi desiderati seguendo uno schema “a scacchiera”.
#include <iostream>
int main() {
const int SIZE = 3;
int matrix[SIZE][SIZE] = {{1, 2, 3},
{4, 5, 6},
{7, 8, 9}};
std::cout << "Elementi a scacchiera con somma di indici di riga e colonna pari: ";
for (int i = 0; i < SIZE; ++i) {
for (int j = 0; j < SIZE; ++j) {
if ((i + j) % 2 == 0) { // Controllo per la somma di indici pari
std::cout << matrix[i][j] << " ";
}
}
}
std::cout << std::endl;
return 0;
}
Elementi dell’anti-diagonale
Usata ad esempio per la convoluzione, consiste nel prendere la totalità delle diagonali secondarie (che sono nell’esempio 1, poi 2,4, poi 3,5,7).
Quindi ad esempio: [i][k - i] andrà a prendere [0][3 - 0], [1][3 - 1], [2][3 - 2], quindi 0,3 poi 1,2 e poi 2,1.
#include<iostream>
using namespace std;intmain(){
constint SIZE = 3;
int matrix[SIZE][SIZE] = {{1, 2, 3},
{4, 5, 6},
{7, 8, 9}};
// Estrazione degli elementi dell'anti-diagonalefor (int k = 0; k < SIZE; ++k) {
cout << "Elementi dell'anti-diagonale " << k + 1 << ": ";
for (int i = 0; i <= k; ++i) {
cout << matrix[i][k - i] << " ";
}
cout << endl;
}
return0;
}
Elementi anti-diagonale con somma di indici pari
Ci sbizzarriamo, a questo punto.
#include <iostream>
int main() {
const int SIZE = 3;
int matrix[SIZE][SIZE] = {{1, 2, 3},
{4, 5, 6},
{7, 8, 9}};
// Estrazione degli elementi dell'anti-diagonale con somma di indici pari
for (int k = 0; k < SIZE; ++k) {
std::cout << "Elementi dell'anti-diagonale con somma di indici pari " << k + 1 << ": ";
for (int i = 0; i <= k; ++i) {
if ((i + (k - i)) % 2 == 0) { // Controllo per la somma di indici pari
std::cout << matrix[i][k - i] << " ";
}
}
std::cout << std::endl;
}
return 0;
}
Manipolazione: Esegui somma tra matrici.
#include <iostream>
const int ROWS = 3;
const int COLS = 3;
void sumMatrices(int mat1[ROWS][COLS], int mat2[ROWS][COLS], int result[ROWS][COLS]) {
for (int i = 0; i < ROWS; ++i) {
for (int j = 0; j < COLS; ++j) {
result[i][j] = mat1[i][j] + mat2[i][j]; // Somma degli elementi corrispondenti
}
}
}
void printMatrix(int matrix[ROWS][COLS]) {
for (int i = 0; i < ROWS; ++i) {
for (int j = 0; j < COLS; ++j) {
std::cout << matrix[i][j] << " "; // Stampa degli elementi
}
std::cout << std::endl;
}
}
int main() {
int matrix1[ROWS][COLS] = {{1, 2, 3},
{4, 5, 6},
{7, 8, 9}};
int matrix2[ROWS][COLS] = {{9, 8, 7},
{6, 5, 4},
{3, 2, 1}};
int result[ROWS][COLS];
sumMatrices(matrix1, matrix2, result); // Somma delle matrici
std::cout << "Matrice 1:" << std::endl;
printMatrix(matrix1);
std::cout << "Matrice 2:" << std::endl;
printMatrix(matrix2);
std::cout << "Risultato della somma:" << std::endl;
printMatrix(result);
return 0;
}
Transposizione: Scambia righe e colonne di una matrice.
Questo programma definisce una matrice 3×3 (matrix), esegue la trasposizione utilizzando la funzione transposeMatrix, e quindi stampa la matrice originale e la matrice trasposta. La funzione printMatrix è utilizzata per stampare le matrici. Durante la trasposizione, viene invertito il numero di righe e colonne, producendo la matrice trasposta
#include <iostream>
const int ROWS = 3;
const int COLS = 3;
void transposeMatrix(int matrix[ROWS][COLS], int result[COLS][ROWS]) {
for (int i = 0; i < ROWS; ++i) {
for (int j = 0; j < COLS; ++j) {
result[j][i] = matrix[i][j]; // Scambio di righe e colonne
}
}
}
void printMatrix(int matrix[ROWS][COLS], int rows, int cols) {
for (int i = 0; i < rows; ++i) {
for (int j = 0; j < cols; ++j) {
std::cout << matrix[i][j] << " "; // Stampa degli elementi
}
std::cout << std::endl;
}
}
int main() {
int matrix[ROWS][COLS] = {{1, 2, 3},
{4, 5, 6},
{7, 8, 9}};
int transposed[COLS][ROWS];
transposeMatrix(matrix, transposed); // Trasposizione della matrice
std::cout << "Matrice Originale:" << std::endl;
printMatrix(matrix, ROWS, COLS);
std::cout << "Matrice Trasposta:" << std::endl;
printMatrix(transposed, COLS, ROWS);
return 0;
}
Determinante: Calcola il determinante di una matrice quadrata.
#include <iostream>
const int SIZE = 3;
int determinant(int matrix[SIZE][SIZE]) {
int det = 0;
det =
matrix[0][0] * (matrix[1][1] * matrix[2][2] - matrix[1][2] * matrix[2][1])
- matrix[0][1] * (matrix[1][0] * matrix[2][2] - matrix[1][2] * matrix[2][0])
+ matrix[0][2] * (matrix[1][0] * matrix[2][1] - matrix[1][1] * matrix[2][0]);
return det;
}
int main() {
int matrix[SIZE][SIZE] = {{1, 2, 3},
{4, 5, 6},
{7, 8, 9}};
int det = determinant(matrix); // Calcolo del determinante
std::cout << "Il determinante della matrice è: " << det << std::endl;
return 0;
}
Inversione: Trova l’inversa di una matrice quadrata.
Chiariamo: non posso fare previsioni certe sul futuro. Nessuno può farne. Si rischia di diventare ridicoli, di essere sbertucciati in futuro dal vituperatissimo “popolo del web”. Tuttavia, possiamo fare alcune riflessioni sul rapporto tra programmatori e intelligenza artificiale (IA), provando a non esacerbarlo e a non immaginare per inerzia scenari modello Terminator anche per il rapporto tra aziende e programmatori informatici.
È probabile che l’IA continuerà a evolversi e a influenzare il lavoro dei programmatori nel tempo, ma ciò non significa che i programmatori diventeranno obsoleti. Piuttosto, potrebbero essere richieste nuove competenze e adattamenti nel campo della programmazione per sfruttare appieno il potenziale dell’IA.
Perchè le IA (non) sostituiranno i programmatori
È vero che l’IA sta avanzando rapidamente in molti campi, inclusa la programmazione stessa. Esistono già strumenti che automatizzano alcune attività di programmazione, come la generazione automatica di codice o la correzione di errori comuni. Questi strumenti possono migliorare l’efficienza e la produttività dei programmatori, e in larga parte già lo fanno. I programmatori hanno un compito complesso, di per sè: progettare soluzioni, farle funzionare, mantenerle nel tempo, renderle comprensibili ai futuri colleghi (si spera).
È chiaro che i programmatori rimangono essenziali per lo sviluppo e il mantenimento dei sistemi basati sull’IA, quindi in parte la risposta è già insita nella domanda, e pensare il contrario è come pensare che i meccanici siano sostituiti dalle automobili che riparano. L’IA richiede un’intensa attività di programmazione per essere ideata, progettata, addestrata e integrata in diverse applicazioni: i programmatori sono tra i principali responsabili della scelta degli algoritmi, della raccolta e preparazione dei dati, nonché della validazione e del miglioramento continuo dei modelli di intelligenza artificiale.
Il processo è comunque supervisionato da uno o più umani, e la maggioranza delle IA sono e rimangono supervisionate. Inoltre, i programmatori svolgono un ruolo fondamentale nell’interpretazione e nell’applicazione dei risultati prodotti dall’IA. Nonostante l’avanzamento dell’IA, è necessaria la competenza umana per comprendere il contesto, valutare l’affidabilità dei risultati e prendere decisioni informate basate sui dati. Mentre l’IA può automatizzare alcune attività di programmazione, i programmatori avranno ancora un ruolo cruciale nello sviluppo, nell’implementazione e nell’applicazione dell’IA. La collaborazione tra l’intelligenza artificiale e i programmatori umani potrebbe portare a risultati più potenti ed efficaci di quanto sia possibile con uno o l’altro da solo.
Le IA possono programmare (entro certi limiti)
È vero che con lo sviluppo accelerato delle intelligenze artificiali, potrebbe verificarsi un impatto significativo sul lavoro dei programmatori. Alcune attività di programmazione più semplici e ripetitive potrebbero essere automatizzate in modo più efficace dalle IA, questo sembra fuori discussione. Il codice pero’ va organizzato, mantenuto, gestito nel tempo, eventualmente riutilizzato.
Tuttavia, ci sono ulteriori ragioni per cui i programmatori continueranno a svolgere un ruolo importante nonostante l’avanzamento delle IA:
Non tutte le attività di programmazione sono facili da automatizzare. La programmazione richiede una comprensione approfondita dei requisiti del software, dell’architettura del sistema e delle logiche complesse.
La risoluzione dei problemi e il pensiero creativo sono spesso necessari per affrontare sfide complesse che vanno oltre la semplice automazione.
La programmazione non si limita solo a scrivere codice. I programmatori sono responsabili della progettazione dei sistemi, dell’architettura dei software e dell’implementazione di soluzioni innovative, oltre alla capacità di gestire e correggere i bug. Questi aspetti richiedono creatività, conoscenza dei domini specifici e competenze tecniche avanzate che vanno oltre la semplice scrittura di codice.
Anche se una parte dell’attività di sviluppo potrebbe essere automatizzata, il mantenimento e il debugging dei sistemi richiedono ancora una competenza umana. Gli errori possono verificarsi in situazioni impreviste e richiedono analisi, correzione e testing da parte dei programmatori per garantire il corretto funzionamento del software.
Le IA possono fornire risultati e suggerimenti, ma la comprensione e l’interpretazione di tali risultati richiedono ancora la competenza umana. I programmatori devono essere in grado di valutare la validità degli output dell’IA, considerare il contesto e prendere decisioni informate basate sui dati.
In definitiva, mentre le IA possono automatizzare alcune attività di programmazione, i programmatori continueranno a svolgere un ruolo cruciale nell’affrontare sfide complesse, nella progettazione di sistemi innovativi e nella gestione dei processi di sviluppo e manutenzione del software. La collaborazione tra programmatori e IA può portare a risultati migliori e più efficienti, piuttosto che sostituire completamente i programmatori stessi.
Per usare una IA per programmare devi saper formulare la domanda
C’è anche in ballo la difficoltà forse più sottovalutata di tutte: per usare una IA per programmare devi saper formulare la domanda. molti programmatori non è detto che sappiano farlo (senza offesa, s’intende).
Punto essenziale, a mio avviso: l’interazione con un sistema basato sull’IA richiede la capacità di formulare domande e specificare correttamente i requisiti. Anche se l’IA può fornire suggerimenti e assistenza nella scrittura del codice, è necessario comunicare in modo chiaro ciò che si desidera ottenere affinché l’IA possa rispondere in modo appropriato.
La capacità di formulare domande efficaci è una competenza chiave per i programmatori che lavorano con l’IA. Richiede una buona comprensione dei concetti di programmazione, della logica e degli algoritmi, nonché una conoscenza del dominio specifico in cui si sta lavorando. E non tutti sono attrezzati in tal senso.
Inoltre è importante sottolineare che la capacità di formulare domande efficaci può essere sviluppata e migliorata nel tempo. I programmatori possono apprendere nuove tecniche di interrogazione e migliorare le proprie competenze comunicative per interagire in modo più efficace con i sistemi basati sull’IA. Tutti (?) i futuri progressi nella progettazione delle interfacce utente potranno semplificare l’interazione con le IA, consentendo ai programmatori di utilizzare strumenti e linguaggi più intuitivi per comunicare con i sistemi di intelligenza artificiale. Ma la capacità di formulare domande in modo efficace è un aspetto importante per utilizzare le IA per programmare, e sarà questo a “fare muro” indirettamente perchè le IA non sostituiranno i programmatori.
La questione della privacy
L’uso di IA proprietarie e chiuse come ChatGPT pone il problema dei dati che i programmatori farebbero trapelare. le aziende potrebbero non essere d’accordo e bloccare le IA preventivamente, o vietarle per policy.
Hai sollevato un’altra questione significativa riguardante l’uso di IA proprietarie e il problema potenziale della gestione dei dati da parte delle aziende. È vero che molte aziende possono essere caute nell’adottare IA proprietarie o chiuse a causa delle preoccupazioni sulla sicurezza dei dati sensibili o sulla violazione della privacy. Le aziende spesso definiscono politiche e linee guida riguardo all’uso dei dati e potrebbero limitare l’accesso alle IA o imporre restrizioni sull’utilizzo di determinate tecnologie. Questo potrebbe comportare la necessità di passare attraverso processi di approvazione o di ottenere il consenso dell’azienda per l’uso di IA.
Mentre strumenti come GitHub favoriscono la collaborazione e la condivisione del codice, ci possono essere casi in cui le aziende desiderano mantenere segrete le proprie soluzioni o proteggere la loro proprietà intellettuale. Tuttavia è importante notare che esistono anche soluzioni basate su IA open source e comunitarie, che promuovono la condivisione dei dati e del codice sorgente. Queste soluzioni possono aiutare a superare le restrizioni imposte dalle IA proprietarie e consentire ai programmatori di lavorare in modo collaborativo e aperto, personalizzandole e tenendole al sicuro nei rispettivi server.
Le IA che programmano possono filtrare progetti informatici assurdi o malposti
Se un imprenditore vuole progettare l’ennesima startup e non ha le idee chiare, la IA può schermare richieste di programmazione con requisiti assurdi o disfunzionali
È possibile che, in alcuni casi, la IA possa schermare richieste di programmazione con requisiti insoliti o poco pratici se non vengono fornite istruzioni chiare e specifiche. L’IA può essere addestrata su dati esistenti e modelli predefiniti, ma se le richieste del cliente restano ambigue, assurdamente ambiziose o poco chiare, l’IA potrebbe comunque produrre risultati incoerenti o non adeguati. Con il vantaggio di averlo fatto senza far sbattere la testa al povero ennesimo programmatore sottopagato.
E vi lamentate? 🙂
Ecco perchè – ulteriore perchè – i programmatori continueranno a servire a lungo, peraltro. Quando un cliente ha idee vaghe o poco chiare per una startup, può essere utile coinvolgere esperti di dominio o consulenti tecnici per affinare e tradurre tali idee in requisiti di programmazione più concreti. Questo aiuterà a fornire indicazioni chiare all’IA o ai programmatori umani sulle aspettative e sugli obiettivi del progetto. Inoltre, i programmatori umani possono svolgere un ruolo importante nel comprendere le richieste del cliente, fare domande di approfondimento e fornire una consulenza tecnica sulla fattibilità e sulle migliori pratiche. La collaborazione tra programmatori e clienti è essenziale per tradurre le idee in requisiti realistici e realizzabili.
L’utilizzo di tecniche di progettazione partecipativa, come workshop o sessioni di brainstorming, può aiutare a stabilire un dialogo aperto e iterativo con il cliente per affinare le idee e sviluppare requisiti di programmazione più solidi. In questo modo, si può evitare che la IA produca risultati basati su requisiti ambigui o poco pratici. (immagine di copertina: DALL-E)
Gestisci Consenso
Per comprendere il flusso di utenti e poter garantire una migliore esperienza d'uso utilizziamo un unico cookie per l'analisi del traffico web. Ci teniamo alla tua privacy e non raccogliamo nulla che non ci interessa e non cediamo nessun dato. Per saperne di più leggi la nostra Privacy Policy.
Funzionale
Sempre attivo
L'archiviazione tecnica o l'accesso sono strettamente necessari al fine legittimo di consentire l'uso di un servizio specifico esplicitamente richiesto dall'abbonato o dall'utente, o al solo scopo di effettuare la trasmissione di una comunicazione su una rete di comunicazione elettronica.
Preferenze
L'archiviazione tecnica o l'accesso sono necessari per lo scopo legittimo di memorizzare le preferenze che non sono richieste dall'abbonato o dall'utente.
Statistiche
Cookie necessario al corretto funzionamento di Matomo Analytics per l'anali del traffico web.L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici anonimi. Senza un mandato di comparizione, una conformità volontaria da parte del vostro Fornitore di Servizi Internet, o ulteriori registrazioni da parte di terzi, le informazioni memorizzate o recuperate per questo scopo da sole non possono di solito essere utilizzate per l'identificazione.
Marketing
L'archiviazione tecnica o l'accesso sono necessari per creare profili di utenti per inviare pubblicità, o per tracciare l'utente su un sito web o su diversi siti web per scopi di marketing simili.