Il pharming rappresenta una minaccia significativa per la sicurezza online, in quanto sfrutta le vulnerabilità nei sistemi DNS e nelle reti per indirizzare gli utenti verso siti web contraffatti. Comprendere il suo significato e adottare le misure di sicurezza adeguate sono passaggi fondamentali per proteggere la propria identità e le proprie informazioni sensibili nell’era digitale.
Pharming con modifica maliziosa del file hosts
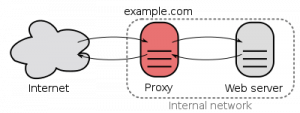
Per comprendere bene il significato del pharming si deve partire dalla struttura stessa di internet: una rete di nodi o host che funziona con commutazione a pacchetto, per cui i nomi di dominio finiscono per essere spesso il punto di compromissione più comune di casi del genere. Ad esempio, voci incorrette nel file hosts di un computer, che modificano la risoluzione del DNS stesso in Windows, finiscono per diventare un bersaglio molto comune per il malware. Una volta riscritto, una richiesta legittima per un sito web sensibile può indirizzare l’utente verso una copia fraudolenta dello stesso, senza che l’utente se ne accorga e sfruttando pagine web identiche nell’aspetto (e a volte con certificati SSL ingannevoli). I personal computer come desktop e laptop sono molto spesso obiettivi di attacchi informatici di pharming perché sono amministrati peggio di quanto non avvenga per altri server o computer connessi in rete.
Pharming con alterazione malevola del router
A differenza della tecnica precedente, l’alterazione della configurazione del router è molto più difficile da rilevare. L’intera LAN che fa uso di quel router ne può risultare compromessa, e in genere i router possono trasmettere informazioni nella risoluzione del DNS in modo ingannevole in due modi: errata configurazione delle impostazioni esistenti o, in alcuni casi, riscrittura completa del firmware Molti router consentono infatti all’amministratore di specificare un particolare DNS di fiducia al posto di quello suggerito da un nodo superiore (che è tipicamente l’ISP o Internet Service Provider). Un attacco malevolo potrebbe pertanto specificare un server DNS sotto la propria gestione, invece di uno legittimo, sottraendo così tutti i dati personali che passano dall’utente ignaro. Il pharming è in effetti solo uno dei molti attacchi che il firmware malintenzionato può essere in grado di effettuare; altri includono l’intercettazione, gli attacchi attivi dell’uomo nel mezzo e la registrazione del traffico. Non sempre gli antivirus si accorgono di queste situazioni, e spesso può essere richiesto l’intervento di personale tecnico specializzato. Molte problematiche, di interesse per lo più teorico, riguardano il fatto che i router siano facilmente soggetti ad attacchi a dizionario (brute force), perchè non prevedono limitazioni se uno prova ad inserirne più di una di seguito per tentativi.
Alcuni esempi di pharming
Per comprendere meglio come funziona il Pharming, possiamo prendere in considerazione alcuni esempi pratici:
- Attacchi al Sistema DNS: Gli aggressori possono compromettere i server DNS, sostituendo gli indirizzi IP dei siti legittimi con quelli dei loro siti contraffatti. In questo modo, quando un utente tenta di accedere al sito legittimo, viene reindirizzato verso il sito malevolo.
- Manipolazione del Router: Gli aggressori possono sfruttare vulnerabilità nei router domestici o aziendali per modificare le impostazioni DNS. Questo consente loro di dirottare il traffico verso siti web contraffatti senza che gli utenti ne siano consapevoli.
- Infezioni di Malware: Alcuni tipi di malware possono installare componenti sul computer dell’utente che modificano le impostazioni DNS o inseriscono voci false nel file hosts, indirizzando così l’utente verso siti web malevoli.
Cosa cambia tra phishing e pharming
C’è una differenza sostanziale tra i due: mentre il phishing si concentra sull’ingannare gli utenti attraverso comunicazioni fraudolente per ottenere informazioni sensibili, il pharming manipola l’infrastruttura di rete o i dispositivi degli utenti per indirizzarli verso siti web contraffatti senza il loro coinvolgimento diretto.
Il phishing e il pharming sono entrambi tipi di attacchi informatici che mirano a ottenere informazioni personali o sensibili dagli utenti, ma differiscono nel modo in cui vengono eseguiti e nell’approccio utilizzato per raggiungere il loro obiettivo.
Phishing:
- Nel phishing, gli aggressori inviano messaggi di posta elettronica, SMS o altri tipi di comunicazioni che sembrano provenire da fonti affidabili, come istituti finanziari, aziende o servizi online.
- Questi messaggi solitamente chiedono agli utenti di fornire informazioni personali, come password, dati di accesso, numeri di carte di credito, o di cliccare su link che li indirizzano verso siti web contraffatti.
- Il phishing spesso si basa sulla persuasione e sulla manipolazione emotiva per indurre gli utenti a fornire volontariamente le proprie informazioni sensibili.
Pharming:
- Il pharming coinvolge la manipolazione del sistema di risoluzione dei nomi di dominio (DNS) o delle impostazioni di routing di una rete al fine di indirizzare gli utenti verso siti web contraffatti senza il loro consenso o la loro consapevolezza.
- Gli attacchi di pharming possono avvenire senza che l’utente compia alcuna azione, poiché vengono manipolati i sistemi di rete o i dispositivi di destinazione per reindirizzare il traffico web verso siti falsi.
- A differenza del phishing, il pharming non richiede l’interazione diretta degli utenti e può essere più difficile da individuare, poiché non dipende dalla persuasione o dall’inganno degli utenti.
Proteggersi dal Pharming: Consigli per la Sicurezza Online
Per proteggersi dalle minacce del Pharming, è fondamentale adottare le seguenti misure di sicurezza:
- Mantenere il Software Aggiornato: Assicurarsi che tutti i dispositivi e i software siano aggiornati con le ultime patch di sicurezza per correggere eventuali vulnerabilità.
- Utilizzare Soluzioni Antimalware: Installare e mantenere aggiornati software antimalware affidabili per proteggere i dispositivi da malware che potrebbero essere utilizzati per condurre attacchi di Pharming.
- Verificare i Certificati SSL/TLS: Prima di inserire informazioni sensibili su un sito web, verificare sempre che la connessione sia protetta utilizzando un certificato SSL/TLS valido.
Foto di Simon da Pixabay