
Senziente è un termine che si riferisce alla capacità di percepire o provare sensazioni, emozioni e coscienza. Gli esseri senzienti sono quindi capaci di esperire sensazioni come piacere, dolore, gioia o tristezza, e possono avere una forma di coscienza che li rende consapevoli di sé e del loro ambiente circostante. Questo termine è spesso utilizzato in contesti etici e filosofici per discutere dei diritti e del trattamento degli animali, poiché si ritiene che molte specie animali siano senzienti e capaci di provare sensazioni e emozioni simili a quelle umane. Inoltre, il concetto di “esseri senzienti” può anche essere esteso a contesti fantascientifici o di intelligenza artificiale, dove si discute della possibilità di creare macchine o entità che siano dotate di coscienza e capacità di percepire e provare emozioni.
Tag: Mondo IA 🤖
-

Confronto ChatGPT e Google: quali sono le differenze chiave?
Tutti usiamo Google come ChatGPT, oggi: ma cosa cambia realmente tra un LLM e un motore di ricerca?
La tecnologia dell’intelligenza artificiale (AI) sta rivoluzionando il modo in cui interagiamo con le informazioni e con gli strumenti di ricerca online. Due dei principali player in questo campo sono ChatGPT e Google, entrambi con approcci diversi e caratteristiche uniche. In questo articolo, esploreremo le differenze chiave tra ChatGPT e Google, e scopriremo come queste tecnologie stanno cambiando il modo in cui cerchiamo e utilizziamo le informazioni online.
Differenze tra ChatGPT e Google

ChatGPT utilizza un approccio basato sulla conversazione, dove l’utente può chiedere domande e ricevere risposte personalizzate. Google, d’altra parte, utilizza un approccio basato sulla ricerca di parole chiave, dove l’utente digita una query e riceve una lista di risultati pertinenti.
ChatGPT utilizza un algoritmo di apprendimento automatico che si basa su un modello di linguaggio naturale per comprendere le domande degli utenti e fornire risposte accurate. Google, invece, utilizza un algoritmo di ricerca basato su un modello di ranking che prende in considerazione fattori come la rilevanza, la popolarità e la qualità dei contenuti.
ChatGPT ha un’interfaccia utente semplice e intuitiva, con un campo di testo dove l’utente può digitare le domande. Google, d’altra parte, ha un’interfaccia utente più complessa, con una barra di ricerca e una serie di opzioni avanzate per la ricerca.
Vantaggi e svantaggi di ChatGPT
+ Risposte personalizzate e contestuali
+ Capacità di comprendere le domande complesse
+ Interfaccia utente semplice e intuitivaSvantaggi:
+ Limitazioni nella comprensione del linguaggio naturale
+ Possibilità di errori o risposte inaccurate
+ Dati di training limitati rispetto a GoogleVantaggi e svantaggi di Google
Vantaggi:
+ Risultati di ricerca più completi e pertinenti
+ Capacità di gestire query complesse e ambigue
+ Integrazione con altri servizi GoogleSvantaggi:
+ Risultati di ricerca possono essere influenzati da fattori come la pubblicità e la popolarità
+ Interfaccia utente più complessa e difficile da utilizzare
+ Possibilità di risultati di ricerca non pertinenti o obsoletiUn po’ di esempi…
Un utente vuole sapere quale sia la miglior strategia per investire in azioni. ChatGPT potrebbe fornire una risposta personalizzata e contestuale, come “La miglior strategia per investire in azioni dipende dai tuoi obiettivi finanziari e dal tuo livello di rischio. Potresti considerare di diversificare il tuo portafoglio e di investire in azioni a lungo termine.” Google, d’altra parte, potrebbe fornire una lista di risultati di ricerca che includono articoli e siti web che offrono consigli e strategie per investire in azioni.
Un utente vuole sapere come posso migliorare la sua salute fisica e mentale. ChatGPT potrebbe fornire una risposta personalizzata e contestuale, come “Per migliorare la tua salute fisica e mentale, potresti considerare di fare esercizio fisico regolarmente, di mangiare una dieta equilibrata e di praticare la meditazione o lo yoga.” Google, d’altra parte, potrebbe fornire una lista di risultati di ricerca che includono articoli e siti web che offrono consigli e strategie per migliorare la salute fisica e mentale.
L’era dell’intelligenza artificiale ha portato a una crescente diffusione dei modelli linguistici di grandi dimensioni (LLM, Large Language Models) e all’evoluzione dei motori di ricerca. Sebbene entrambi siano strumenti potenti per accedere alle informazioni, il loro funzionamento e gli output che generano sono profondamente diversi.
Un LLM è un modello di intelligenza artificiale addestrato su enormi quantità di dati testuali. Il suo obiettivo principale non è cercare informazioni esistenti sul web, ma generare testo coerente basandosi su ciò che ha “imparato” durante l’addestramento. Esempi di LLM includono GPT (come ChatGPT), Claude e Gemini. In generale un LLM come ChatGPT:
- Analizza il contesto della richiesta e genera una risposta basata sulla probabilità delle parole successive.
- Non accede direttamente a internet per informazioni in tempo reale (a meno che non sia collegato a un database esterno o a strumenti di ricerca).
- Può elaborare, sintetizzare e riformulare contenuti basandosi su dati passati
Un motore di ricerca, come Google o Bing, è un sistema che indicizza il web e fornisce risultati pertinenti basandosi su parole chiave. La sua funzione principale è recuperare pagine web pertinenti alle query degli utenti. Di base quest’ultimo
- Indicizza miliardi di pagine web attraverso crawler automatici.
- Classifica i risultati in base a criteri di rilevanza e SEO.
- Fornisce link diretti a fonti esterne aggiornate.
I modelli di linguaggio (LLM) come ChatGPT e i motori di ricerca (Google, Bing) sono spesso usati come se fossero intercambiabili, ma in realtà funzionano in modo molto diverso.
- Motori di ricerca
- Forniscono risultati pertinenti in base alla query e alla cronologia dell’utente.
- Offrono fonti esplicite e verificabili.
- Non generano nuove informazioni, ma recuperano quelle esistenti.
- LLM (ChatGPT, Gemini, ecc.)
- Creano risposte combinando fonti probabilisticamente (inferenza).
- Possono commettere errori logici o creare informazioni inesatte.
- A volte rifiutano di rispondere per incertezza o sensibilità del tema.
- Non sempre citano chiaramente le fonti.
Mentre Google può mostrare contenuti fuorvianti, non genera spiegazioni errate come un LLM potrebbe fare. La differenza chiave sta nella trasparenza e nella modalità di elaborazione delle informazioni: i motori cercano, gli LLM assemblano parole. Entrambi possono essere manipolabili con tecniche specifiche.
Per una ricerca in ambito programmazione, ad esempio, i motori di ricerca funzionano meglio, perché si cerca la competenza, l’esperienza e la conoscenza di chi ha già risolto un problema con successo. Si può certamente programmare con l’aiuto delle IA, spesso con buoni risultati, ma lavorare così senza supervisione può essere rischioso. Il copia-incolla passivo, diffuso tra molti studenti, è meno “sano” rispetto all’apprendimento attivo che si potrebbe fare consultando i forum di programmazione.
Bing ha da qualche tempo (febbraio 2025) integrato un LLM dentro i motori, ma non sembra una buonissima idea: la sintesi potrebbe essere scorretta e potrebbe non essere ciò che stava cercando l’utente programmatore.
10 Esempi Pratici di Come un LLM Risponde
- “Spiegami la teoria della relatività in modo semplice” → Fornisce un testo sintetizzato e spiegato in modo accessibile.
- “Scrivimi una poesia sul mare” → Genera una poesia originale.
- “Riassumi il libro ‘1984’ di George Orwell” → Produce un riassunto basato sulla conoscenza acquisita durante l’addestramento.
- “Dimmi 5 modi per migliorare la concentrazione nello studio” → Fornisce una lista di suggerimenti generici.
- “Crea un breve dialogo tra un astronauta e un alieno” → Genera un testo creativo e coerente.
- “Scrivi una lettera di presentazione per un lavoro di ingegnere” → Fornisce un testo personalizzato in base alla richiesta.
- “Come funzionano le reti neurali?” → Spiega il concetto in modo dettagliato senza fornire link.
- “Scrivi una battuta su i programmatori” → Genera una battuta originale.
- “Aiutami a scrivere una sceneggiatura breve per un cortometraggio horror” → Crea una storia coerente basata sul genere richiesto.
- “Spiega la differenza tra HTTP e HTTPS” → Fornisce una spiegazione tecnica sintetica.
10 Esempi Pratici di Come un Motore di Ricerca Risponde
- “Ultime notizie sulla guerra in Ucraina” → Mostra articoli recenti da fonti di notizie aggiornate.
- “Dove si trova il ristorante più vicino aperto ora?” → Fornisce una mappa con le localizzazioni.
- “Recensioni sul nuovo iPhone” → Elenca articoli e video di recensioni.
- “Quanto costa un biglietto aereo per Tokyo a dicembre?” → Mostra siti di comparazione prezzi in tempo reale.
- “Ricetta per la carbonara autentica” → Fornisce link a siti di cucina con dettagli.
- “Chi ha vinto il Premio Nobel per la letteratura 2023?” → Mostra risultati aggiornati con fonti affidabili.
- “Miglior laptop per studenti nel 2024” → Fornisce liste e guide all’acquisto.
- “Come risolvere l’errore 404 su WordPress?” → Mostra tutorial da blog tecnici.
- “Quanto è alto il Monte Everest?” → Fornisce un dato esatto con una fonte verificata.
- “Qual è il significato della vita secondo diversi filosofi?” → Elenca articoli accademici e discussioni filosofiche.
I modelli LLM e i motori di ricerca hanno funzioni diverse: i primi generano contenuti e spiegazioni basate sui dati acquisiti, mentre i secondi forniscono collegamenti diretti a fonti esterne aggiornate. A seconda delle esigenze, un utente può scegliere se interagire con un LLM per una sintesi o una spiegazione, o utilizzare un motore di ricerca per accedere a informazioni aggiornate e verificate. Comprendere queste differenze permette un uso più efficace di entrambe le tecnologie nella ricerca e nella generazione di contenuti.
-

Usare l’intelligenza artificiale per rilevare il plagio di immagini e testi
Se vuoi rilevare il plagio, puoi semplicemente utilizzare la tecnologia e gli strumenti moderni. In passato, infatti, era piuttosto difficile scoprire se qualcuno avesse rubato immagini o testo da un’altra fonte. La mancanza di tecnologia nella ricerca del plagio ha comportato un aumento dei casi di questo tipo, e naturalmente sul web non è semplice arginare il problema. Oggi il plagio è potenzialmente aumentato, e le persone non sono ancora consapevoli delle sue pessime, potenziali conseguenze. Se vuoi rilevare casi del genere, per fortuna, puoi facilmente fare affidamento sulla tecnologia moderna. Di seguito, pertanto, abbiamo discusso i migliori strumenti e tecnologie che possono aiutarti a identificare un’immagine e un plagio testuale come un vero esperto nel settore.
In che modo l’intelligenza artificiale aiuta a trovare il plagio?
L’intelligenza artificiale è oggi utilizzata in ogni parte della nostra vita: puoi vederla penetrare in quasi tutti i campi di lavoro, nelle più diverse attività , ed è a volte patognomonico di un modo di pensare che pensa più a questo che alla sostanza (purtroppo, sono anche i limiti della nostra percezione tecnologica). Saresti sorpreso di sapere che oggi il rilevamento del plagio è diventato addirittura facile anche grazie all’intelligenza artificiale.
In passato venivano utilizzate tecniche di confronto manuale per trovare duplicazioni nelle immagini o nel testo, ma oggi non è possibile nè conveniente farlo. Questo perché oggi sul web troveresti centinaia di miliardi di parole e immagini, e diventa davvero difficile effettuare con comodità questa operzione. Non è praticabile che tu vada confrontare i tuoi contenuti con questa quantità di contenuti, da solo, senza l’aiuto di un’idonea tecnologia a supporto. È qui che gli strumenti basati sull’intelligenza artificiale entrano in gioco per darti una mano.
Rilevamento del plagio nel testo con l’aiuto di AI e algoritmi avanzati
L’intelligenza artificiale è in grado di aiutarti molto a confrontare il testo e a trovare eventuali casi del genere. Una delle tecnologie utilizzate nel rilevamento del plagio è la sottosequenza comune più lunga. Questo metodo di controllo del plagio, effettuata mediante strumenti basati sull’intelligenza artificiale, si riferisce al confronto della sequenza di parole da destra a sinistra. Questa tecnologia viene generalmente utilizzata quando devi confrontare il testo con una risorsa specifica sul web. Un altro modo per trovare casi di questo tipo utilizzando software antiplagio è il cosiddetto contenimento: la tecnica di contenimento è molto diffusa in quanto crea un corpus attorno al testo che viene immesso come input. Il corpus viene quindi suddiviso con le copie dei contenuti disponibili nel database interno dello strumento.
Diverse risorse software antiplagio utilizzano metodi diversi per controlla plagio, ma l’unica cosa comune in tutte è che usano l’intelligenza artificiale per comprendere i tuoi contenuti, e confrontarli con miliardi di altre pagine presenti sul web. Una delle tecniche più popolari basate sull’intelligenza artificiale utilizzate per trovare il plagio testuale è il metodo dividi e scansiona. In questo metodo, i tuoi contenuti vengono suddivisi in piccole divisioni e confrontati individualmente con il database di cui sopra. Con questa tecnica, un correttore di plagio può facilmente rilevare plagio accidentale, plagio cosiddetto “a mosaico” e addirittura contenuto mal parafrasato.
In breve, se vuoi rilevare il plagio testuale oggi, dovresti assicurarti di utilizzare software antiplagio online alimentato dall’intelligenza artificiale.
Detection dell’immagine copiata con l’aiuto dell’intelligenza artificiale
Oggi il problema del plagio visivo è aumentato parecchio: questo perché troppe persone pensano che sia possibile duplicare le immagini senza il permesso del creatore originale (cosa che, ricordiamo, non deve mai essere effettuata: meglio usare immagini libere da diritti e riutilizzabili). Innanzitutto, devi considerare che il plagio delle immagini ha gli stessi pessimi effetti del plagio testuale. Ma oggi puoi trovare il plagio delle immagini ed evitarlo con l’aiuto della ricerca di immagini via AI (Artificial Intelligence).
La ricerca inversa di immagini è la tecnica ormai in primo piano, anch’essa è alimentata dall’intelligenza artificiale. L’ricerca tramite immagine la tecnica è quella che può consentire la ricerca per immagini al posto di quella testuale. Il metodo di ricerca convenzionale prevede l’utilizzo di parole chiave, mentre la ricerca foto permette di farlo in modo “visuale”.
Con l’aiuto della tecnica ricerca tramite immagine puoi trovare immagini simili pubblicate sul web, più o meno come la tua. Artificiale intelligence, OCR, CBIR e vari algoritmi di riconoscimento delle immagini sono utilizzati dai moderni strumenti di ricerca inversa , che assicurano che l’accuratezza dei risultati non sia compromessa. Qualora si immetta un’immagine nell’utilità ricerca inversa immagini, lo strumento permetterà di analizzarlo e comprenderne il contenuto. L’immagine verrebbe scomposta in formato binario e quindi verrebbe confrontata con miliardi di pagine sul Web, un’operazione dispensiosa computazionalmente che solo un software del genere potrebbe effettuare. Le immagini corrispondenti, poi, verranno mostrate nei risultati. È così possibile scoprire i siti Web, le pagine e gli eventuali account dove la tua immagine, quella su cui detieni i diritti, venga eventualmente utilizzata in modo improprio.
Conclusioni
Sono forse finiti i giorni in cui dovevi assumere un professionista per confrontare e monitorare l’originalità dei tuoi contenuti testuali e visivi. Oggi puoi farlo da solo, con l’aiuto del controllo plagio online e le meraviglie della ricerca immagini inversa. Esistono centinaia di strumenti di scansione disponibili sul Web, ma ti consigliamo generalmente di scegliere quelli che utilizzano l’intelligenza artificiale e tattiche avanzate per rilevare la duplicazione. Scrittori, fotografi professionisti, designer, studenti e webmaster possono utilizzare questi strumenti online per garantire unicità e originalità ai loro contenuti.
-

Guida pratica a Rocket Hosting (secondo noi)
Rocket Hosting è un provider italiano specializzato in soluzioni hosting ad alte prestazioni, con un focus particolare su WordPress, Prestashop e infrastrutture cloud per progetti business-critical. In questo articolo vedremo come le tecnologie adottate – SSD NVMe, LiteSpeed, Redis, sistemi di backup avanzati – contribuiscano a garantire tempi di risposta rapidissimi, elevata affidabilità e scalabilità, oltre a illustrare le principali caratteristiche tecniche dei piani condivisi, cloud VPS e server dedicati.
1. Architettura Hardware e Storage NVMe
- Dischi SSD NVMe Enterprise: Rocket Hosting sfrutta storage NVMe di classe enterprise, fino a 16 volte più veloce di un tradizionale SSD SATA. Gli NVMe comunicano direttamente con la CPU via PCI-Express, riducendo drasticamente le latenze di I/O (< 100 µs) ed aumentando la IOPS sostenute (> 500 000 IOPS)
- RAID 10 e ridondanza: ciascun nodo monta array RAID 10, che combinano striping (maggiore throughput) e mirroring (fault tolerance), garantendo sia velocità di scrittura/lettura sia protezione dei dati contro la perdita in caso di guasto disco.
- CPU e memoria dedicate: anche nei piani shared hosting, Rocket Hosting riserva risorse CPU e RAM isolate, evitando “noisy neighbour” e assestamento delle performance sotto carico (rockethosting.it).
2. Software Web Server e Caching Avanzato
- LiteSpeed Web Server: rispetto a Apache o Nginx, LiteSpeed gestisce fino al 50% in più di richieste concorrenti e supporta nativamente HTTP/2, QUIC/HTTP3 e PHP LSAPI per accelerare l’esecuzione degli script PHP (rockethosting.it).
- LiteSpeed Cache Plugin: integrato per WordPress e Prestashop, crea cache full-page in memoria e su disco, riducendo la generazione dinamica delle pagine e abbattendo i tempi TTFB (Time To First Byte) sotto i 50 ms nelle condizioni ottimali.
- Redis Object Cache: sistema di cache object-level in-memory per WordPress, che memorizza i risultati delle query al database e riduce il carico MySQL fino al 70% (rockethosting.it).
3. Infrastruttura di Rete e Uptime
- BGP Anycast: rete globale con instradamento Anycast, che indirizza le richieste utente al POP più vicino, ottimizzando latenza e resilienza in caso di interruzioni locali.
- 99,9% Network Uptime: SLAs garantiti su disponibilità di rete, con monitoraggio in real-time e sistemi automatici di failover (rockethosting.it).
- Mitigazione DDoS: protezione hardware e software contro attacchi volumetrici e di livello applicativo, grazie a filtri L3/L4 e WAF integrato (mod_security, regole OWASP).
Il BGP Anycast è una tecnica di routing che permette a più nodi distribuiti geograficamente di annunciare lo stesso prefisso IP attraverso il protocollo BGP; in pratica, ogni router Internet decide in base alla metrica di percorso (tipicamente il numero di hop o il costo AS\_PATH) a quale istanza inoltrare il traffico, indirizzandolo così al POP più vicino o più performante. Questo modello riduce significativamente la latenza per l’utente finale, migliora la resilienza in caso di guasti – poiché se un nodo diventa indisponibile il traffico viene automaticamente ridirezionato altrove – e offre una prima linea di difesa contro attacchi DDoS, poiché il carico può essere distribuito tra più siti, alleggerendo la pressione su ciascuna singola location.
4. Backup, Staging e Ripristino
- Backup giornalieri avanzati: snapshot incrementali e full ogni 24 ore, conservati fino a 30 giorni, con ripristino point-in-time in pochi clic dal pannello di controllo (rockethosting.it).
- Cloning e Staging: per piani WordPress e Cloud Business, è possibile creare ambienti di staging isolati per testare aggiornamenti plugin o modifiche al tema, poi promuovere i cambiamenti in produzione con un semplice push.
- Controllo versioning: integrazione Git nativa, per gestire il deploy automatico via webhook e mantenere traccia delle modifiche al codice.
In ambito hosting e sviluppo web i termini cloning, staging e versioning indicano tre pratiche distinte (ma spesso integrate in un flusso di lavoro) che aiutano a mantenere controllati e sicuri i processi di sviluppo, test e rilascio di un sito o di un’applicazione.
1. Cloning
Il cloning (o “clonazione”) è la creazione di una copia esatta — file, database e configurazioni — di un ambiente esistente.
- Scopo: avere un duplicato identico dell’ambiente di produzione (o di qualsiasi altro ambiente) per effettuare test, debug o migrazioni senza rischiare di compromettere il sito live.
- Come funziona: il sistema crea uno snapshot completo o incrementale dei dati e lo ripristina in un’area isolata del server o in un altro server; può essere avviato manualmente o via script.
- Vantaggi: rapidità nel ripristino, facilità di migrazione tra server o provider, sicurezza nell’eseguire modifiche disruptive su una copia anziché sul sito live.
2. Staging
Lo staging (o “ambiente di staging”) è un’area di test separata, dove si applicano e verificano in anteprima tutte le modifiche prima del rilascio in produzione.
- Scopo: simulare fedelmente il comportamento del sito live per validare nuove funzionalità, aggiornamenti di plugin/tema o interventi di design.
- Come funziona: partendo da un clone dell’ambiente di produzione, si installano le modifiche (codice, contenuti, configurazioni) e si testano tutte le integrazioni (database, API esterne, performance). Solo dopo il via libera, si “promuovono” le modifiche in produzione.
- Vantaggi: riduce drasticamente il rischio di downtime o errori visibili agli utenti finali, perché eventuali bug vengono intercettati in uno spazio isolato e non pubblico.
3. Versioning
Il versioning (controllo di versione) è la pratica di tracciare ogni modifica apportata al codice sorgente e, talvolta, anche ai contenuti e alle configurazioni.
- Strumenti principali: Git (con repository su GitHub, GitLab, Bitbucket, ecc.) oppure sistemi alternativi come Subversion o Mercurial.
- Come funziona: ogni “commit” registra uno snapshot del progetto, con messaggi descrittivi, autore e timestamp. Branch e tag permettono di lavorare in parallelo su feature diverse, gestire release e rilasciare patch di bugfix.
- Vantaggi:
- Tracciabilità: si sa esattamente “chi ha cambiato cosa e quando”.
- Rollback: si può tornare a una versione precedente in caso di regressioni.
- Collaborazione: più sviluppatori possono lavorare in contemporanea cercando di unire (merge) i propri contributi.
- Automazione: sistemi di Continuous Integration/Continuous Deployment (CI/CD) scatenano build, test automatici e deploy in staging o produzione al verificarsi di un commit su un branch specifico.
Integrazione delle tre pratiche
Un workflow tipico potrebbe essere:
- Clonazione dell’ambiente di produzione in un’area di staging.
- Sviluppo delle nuove funzionalità in locale o in branch Git dedicati (versioning).
- Deploy automatico in staging per eseguire test funzionali, di performance e di sicurezza.
- Merge del branch stabile nel ramo
mainoproductione promozione in produzione (pull dal repository e sincronizzazione dei file/configurazioni).
In questo modo, ogni passaggio (cloning → staging → versioning) contribuisce a un rilascio più sicuro, controllato e tracciabile.
5. Piattaforme e Gestione
- Pannello cPanel o Plesk (VPS/Dedicati): scelta flessibile tra due dei più popolari pannelli di controllo, con gestione account, domini, database e certificati SSL in pochi click (rockethosting.it).
- Accesso SSH e SFTP: per amministratori e sviluppatori, accesso shell root (su VPS/Dedicati), gestione chiavi SSH e trasferimento sicuro dei file.
- Gestione Full Managed: i sistemisti di Rocket Hosting si occupano di patching OS, monitoraggio 24/7, ottimizzazioni di sistema e aggiornamenti di sicurezza, liberando il cliente dalle attività di manutenzione server (rockethosting.it).
6. Sicurezza e Compliance
- Firewall e WAF: protezioni a livello di host e applicazione, con mod_security e regole personalizzate per bloccare exploit noti (SQL injection, XSS, RCE).
- Protezione Malware: scansione file system, quarantena automatica e supporto al ripristino in caso di compromissione.
- Certificati SSL gratuiti: Let’s Encrypt integrato, con rinnovo automatico ogni 90 giorni.
- GDPR-Ready: data center in UE, politiche privacy e cookie conformi al regolamento europeo.
7. Prezzi e Convenienza
Piano Partenza Periodo Hosting WordPress € 42,00/anno + IVA annuale Hosting Linux condiviso € 29,90/anno + IVA annuale Cloud Hosting Business € 34,90/mese + IVA mensile Rivenditori & Web Agency € 19,90/anno + IVA annuale Tutti i piani includono SSL gratuito, backup giornalieri, risorse dedicate e migrazione gratuita del sito (rockethosting.it). La formula “30 giorni soddisfatti o rimborsati” riduce i rischi di adozione iniziale.
Rocket Hosting si propone come soluzione completa per chi cerca un hosting italiano ad alte prestazioni, con architettura NVMe, LiteSpeed, caching avanzato e supporto full managed. Grazie a un’infrastruttura ridondata, monitoring continuo e un team di sistemisti esperti, è ideale per progetti WordPress, e-commerce Prestashop e applicazioni business che richiedono affidabilità e scalabilità. Per chi desidera un bilanciamento ottimale tra prezzo e tecnologia di ultima generazione, Rocket Hosting merita sicuramente un test approfondito.
Per ulteriori approfondimenti su Rocket Hosting visita il sito ufficiale.
-

Cos’è Nudify, cosa fa e cosa si rischia (NSFW)
È stato scoperto da pochissimo, e nel modo peggiore: un determinato tipo di intelligenza artificiale generativa sta attualmente generando falsi nudi di persone reali mediante l’app nota come “nudify” (significativamente tra i trend di Google, ad oggi). Dovrebbe trattarsi di un clone di un’app molto simile che è nota nel dark web come Clothoff, anch’essa in grado di generare nudi fake a partire da foto vestite, con tutte le implicazioni etiche e legali che ne conseguono. In alcuni casi, peraltro, è stato rilevato che l’app viene usata come “esca” per attrarre visitatori e curiosi ignari a pagare all’interno di siti dubbi o addirittura truffa.
Non è la prima volta che si parla di deep nude, i nudi artificiali creati senza consenso del soggetto, e temiamo che se ne parlerà ancora per molto come una minaccia.
Le app tipo “Nudify” e Clothoff (potrebbero esisterne altre con nomi diversi) consentono all’utente di elaborare una normale foto vestita di qualcuno e di usare l’intelligenza artificiale per creare un’immagine di nudo finto di quella persona. Questi nudi fake possono essere condivisi, causando significative implicazioni traumatiche, psicologiche e sociali per il soggetto vittima. Inoltre, l’atto di creare o condividere nudi, veri o falsi, può comportare conseguenze gravi a livello legale, che nessun utente dovrebbe sottovalutare.
Di fatto non si parlerà mai abbastanza dei rischi annessi a questa tipologia di app: dalle implicazioni legali che ne conseguono, che in genere gli utenti ignorano o sottovalutano, fino alla violazione della privacy di milioni di persone. Non c’è molto da fare a livello di prevenzione, purtroppo, se non il fatto di abituare le persone ad un utilizzo etico e consapevole delle nuove tecnologie, considerando che si tratta di un reato abbastanza grave effettuare un’operazione del genere su una foto senza aver avuto il consenso della persona ritratta. Non è neanche chiaro chi o quale azienda o persona abbia realizzato Clothoff e Nudify, non si sa neanche a chi vadano i compensi per l’uso del servizio – ma sembra sicuro che il sito tenda a cambiare ogni volta e potrebbe essere stato bloccato in alcuni paesi. Si sconsiglia vivamente di farne uso e di visitarlo, sia perchè gli accessi potrebbero essere tracciati e sia perchè si potrebbero contrarre malware sul proprio computer o telefono.
-

Guida pratica alla sentiment analysis: nascita, esempi pratici, uso, limiti
“Analisi del sentimento” (per tradurre in italiano sentiment analysis) è una traduzione un po’ maccheronica, e soprattutto non rende giustizia a ciò che questa affascinante branca dell’intelligenza artificiale effettivamente è. Analisi dell’umore, ad esempio, potrebbe rendere meglio l’idea, ma sarebbe anche meglio specificare il contesto: analisi dell’umore sulla base di un testo scritto.
In breve: L’analisi del sentiment è un procedimento automatizzato che permette di analizzare il testo al fine di determinare il sentimento espresso, che può essere positivo, negativo o neutro. Questa tecnica trova molteplici applicazioni, tra cui il monitoraggio dei social media, la gestione dell’assistenza clienti e l’analisi dei feedback da parte dei clienti.
Origini e fondamenti della disciplina
L’analisi del sentiment ha compiuto enomi passi avanti nel capire e classificare le emozioni espresse dai testi. I testi che sono tipicamente analizzati in questo ambito, infatti, sono per esempio commenti sui social oppure, più comunemente, recensioni dei prodotti online: analizzare l’umore dei testi e classificarlo può essere utile a dare un feedback “umorale” all’azienda, facendogli capire quanto siano soddisfatti (o meno) i suoi clienti. In prima istanza, quindi, la sentiment analysis non fa altro se non apporre un’etichetta “positivo” o “negativo” ad un testo, cosa che è possibile fare in modo molto semplice sfruttando librerie come autolabel. Nella documentazione viene riportato l’esempio di classificazione binaria di una recensione cinematografica, ovviamente nei termini di recensione positiva e negativa. Nella valutazione intervengono aspetti sintattici (come si scrive) e semantici (cosa si vuole tramettere) di vario tipo, tecniche di scomposizione del testo in linguaggio naturale (che già esistevano da tempo), attribuzione di punteggi e valutazione finale su base statistica (rating come media pesata, ad esempio). Va tenuto conto che la sentiment analysis deve essere in grado di gestire sia casi semplici (in cui il sentiment è lampante: “X non mi piace“) che casi meno ovvi (doppie negazioni: “X non mi dispiace“, sarcasmo e ironia: “Adoro uscire durante un temporale!“, ambiguità “Mi piace X, ma non lo consiglierei davvero a nessuno“).
Oltre ad un discorso di polarizzazione buoni/cattivi, bianchi/neri ecc., la classificazione del sentiment potrebbe mettere in ballo una gamma più ampia di stati emotivi, consentendo una valutazione ancora più dettagliata delle opinioni e delle emozioni degli individui. Questo approccio offre un vantaggio significativo nell’interpretazione dei testi e nella comprensione delle dinamiche del sentiment nel contesto della tecnologia per come viene usata nella maggiorparte dei casi pratici. Alla base di questa disciplina sembra esserci uno studio psicologico monumentale risalente a fine anni 60, firmato Gottschalk, Goldine, dal titolo “Misura degli stati psicologici attraverso l’analisi dei contenuti verbali”e reperibile online. Ovviamente l’idea che un sentiment (inteso come umore) sia determinabile in modo univoco solo dal testo (e non pure dal contesto in cui è stato scritto, ad esempio) sarà per molto tempo oggetto di controversie e potenziali controversie, ma la tecnologia sarà comunque in grado di allinearsi alle nuove scoperte riflettendo, come sempre, le varie sfumature scientifiche e/o punti di vista sull’argomento.
Esempi pratici di sentiment analysis in Python (NLTK)
Non mancano soluzioni open source per effettuare questo genere di attività dentro ad un software. Per esempio usando Python 3 e NLTK (Natural Language Toolkit):
import nltk from nltk.sentiment import SentimentIntensityAnalyzer # Creazione dell'istanza del sentiment analyzer sia = SentimentIntensityAnalyzer() # Testo da analizzare text = "..." # Analisi del sentiment sentiment_scores = sia.polarity_scores(text) # Interpretazione dei risultati if sentiment_scores['compound'] >= 0.05: sentiment = "Positivo" elif sentiment_scores['compound'] <= -0.05: sentiment = "Negativo" else: sentiment = "Neutrale" # Stampa dei risultati print("Testo: ", text) print("Sentiment: ", sentiment) print("Sentiment Scores: ", sentiment_scores)In questo esempio, abbiamo sfruttato il SentimentIntensityAnalyzer di NLTK per analizzare il sentiment di un testo. Creiamo un’istanza del sentiment analyzer chiamata sia e passiamo il testo da analizzare. La funzione sia.polarity_scores() restituisce un dizionario di punteggi di sentiment, tra cui il punteggio complessivo chiamato “compound“. Successivamente, interpretiamo il punteggio compound per determinare se il sentiment è positivo, negativo o neutro. Infine, stampiamo il testo, il sentiment e i punteggi di sentiment.
Se scrivo “sono entusiasta del thrash metal“, ad esempio, il sentiment è reputato positivo.

Se invece scrivo di essere molto coinvolto dal genere, viene considerato neutro:

In genere la valutazione è soggettiva ed è uno di quei casi in cui non può che essere così, a ben vedere: il sentiment è sempre relativo al singolo soggetto, e fa parte della relativizzazione delle opinioni che ben conosciamo sul web (e che spesso porta ad effetti collaterali nefasti).
Per eseguire questo codice, ricordo che è necessario avere installato NLTK e scaricare il corpus ‘vader_lexicon‘ eseguendo il comando
nltk.download('vader_lexicon')prima dell’utilizzo (direttamente nel codice, nella quarta riga).
Conclusioni
Di sicuro la sentiment analysis, per quanto non troppo precisa in certi frangenti, risponde ad un’esigenza molto diffusa nelle aziende, su cui vale la pena riflettere: quella di ragionare per forza sui numeri, di calcolare degli indici di qualche tipo su cui ragionare, su cui dedurre, fare previsioni, stilare progettualità. Ma serve davvero? Siamo dell’idea che la tecnologia non sia altro che uno strumento, anche stavolta, nonostante l’insana tendenza che viviamo ogni giorno ad umanizzarla.
Non sappiamo fino a che punto possa essere significativo fare sentiment analysis ad oltranza e, come dire, solo il tempo saprà dirlo. (immagine di copertina: StarryAi, “un robot che verifica i miei sentimenti”)
-

Guida pratica agli expat: chi sono cosa fanno e potenziali problematiche psicologiche
Ti stai chiedendo cosa significa expat e quando usare questa parola? Non è difficile da spiegare: gli expatriate o expat sono persone che vivono al di fuori del proprio paese d’origine, tipicamente per lavoro. In genere si tratta di impiegati in società multinazionali, insegnanti, professionisti o pensionati, ma esiste anche una discreta percentuale di liberi professionisti al loro interno.
Statistiche
Problematiche psicologiche
L’ansia, la solitudine e la nostalgia di casa possono essere sfide importanti da affrontare durante il processo di espatrio. È importante fornire supporto sociale, avere una mentalità aperta e cercare aiuto professionale se necessario per affrontare queste sfide psicologiche. Le problematiche psicologiche comuni tra gli expat possono includere il senso di isolamento, difficoltà nell’adattamento culturale e stress legato al cambiamento.
Etimologia e significato di expat
Il termine expat deriva dai termini latini ex (“fuori”) e patria intesa come paese natale o di origine.
Expat” è una abbreviazione di “expatriate”, un termine che deriva dal latino “expatriatus”, formato dal prefisso “ex” (che significa “fuori da” o “lontano da”) e “patria” (che significa “paese” o “terra natia”). Quindi, “expatriate” letteralmente si riferisce a qualcuno che vive al di fuori del proprio paese d’origine. Questo termine è comunemente utilizzato per descrivere persone che risiedono all’estero per lavoro, studio o altre ragioni, mantenendo una connessione con il proprio paese d’origine.
Ulteriori significati e varianti del termine
Le definizioni del dizionario per il significato attuale della parola includono, da dizionario, “Una persona che vive al di fuori del proprio paese d’origine” oppure, similmente, “che vive in una terra straniera“. Queste definizioni sono piuttosto diverse, a conti fatti, con quelle di altre parole dal significato simile con cui spesso sono confuse, tra cui ad esempio:
- Migrante: “Una persona che si sposta da un luogo a un altro per trovare lavoro o condizioni di vita migliori”, oppure
“Uno che migra: come ad esempio una persona che si sposta regolarmente per trovare lavoro” - Immigrato: “Una persona che viene a vivere in modo permanente in un paese straniero”
L’uso diverso di questi termini per i diversi gruppi di stranieri può essere visto come un’implicazione di sfumature relative alla ricchezza, alla durata prevista del soggiorno, alle motivazioni percepite per il trasferimento, alla nazionalità e persino alla razza. Ciò ha causato controversie, con alcuni studiosi che si sono spinti a sostenere che l’uso tradizionale della parola “expat” avrebbe in alcuni casi avuto connotazioni razziste.
Un uso più antico della parola expat si riferiva a un esule; in alternativa, se usato come sostantivo verbale, l’espatrio può significare l’atto di qualcuno che rinuncia alla fedeltà al proprio Paese d’origine, come nel preambolo della legge sull’espatrio degli Stati Uniti del 1868 che afferma:
‘il diritto di espatrio è un diritto naturale e intrinseco di tutti gli uomini, indispensabile per il godimento dei diritti di vita, libertà e ricerca della felicità‘”.
Sono stati coniati ulteriori neologismi su questa falsariga, tra cui:
- dispatriate, un espatriato che si allontana intenzionalmente dalla propria nazione di origine;
- flexpatriate, un dipendente che viaggia spesso a livello internazionale per lavoro;
- inpatriate, un dipendente inviato da una filiale estera per lavorare nel Paese in cui ha sede un’azienda;
rex-pat, un espatriato “ripetente”, spesso qualcuno che ha scelto di tornare in un Paese straniero dopo aver completato un incarico di lavoro;
sexpat, un espatriato con l’obiettivo di una relazione sessuale a breve o lungo termine (espatriato + turista sessuale).
Il termine “espatriato” è talvolta riportato erroneamente come “ex-patriota”, che è ovviamente un equivoco linguistico sul significato (eggcorn).
- Migrante: “Una persona che si sposta da un luogo a un altro per trovare lavoro o condizioni di vita migliori”, oppure
-

Intelligenza Artificiale e lavoro: una minaccia o un’opportunità?
L’intelligenza artificiale (IA) trova sempre più spesso applicazione nei diversi ambiti della nostra quotidianità, incluso il mondo del lavoro, che può oggi contare su tutta una serie di innovazioni basate su algoritmi di machine learning, dai chatbot all’automazione industriale, fino all’analisi dei big data, in grado di svolgere quello che, fino a poco tempo fa, era lavoro interamente umano. Ma cosa significa tutto ciò? Bisogna davvero preoccuparsi per i risvolti che la tecnologia potrebbe avere sul mercato professionale o, piuttosto, questo cambiamento rappresenta un’opportunità di miglioramento? Cerchiamo di capire meglio cosa sta accadendo.
Foto di Gerard Siderius su Unsplash
IA e automazione: si va verso la fine del lavoro tradizionale?
Una delle prime applicazioni dell’IA in ambito lavorativo riguarda l’automazione delle attività, manifatturiere e non solo. Settori come la produzione, la logistica e il servizio clienti vedono infatti una crescente automazione dei compiti prima riservati agli operatori umani, con macchine che svolgono lavori di vario genere in tempi ridotti e con la massima efficienza, un cambiamento che ha portato a previsioni anche catastrofiche, secondo cui milioni di posti di lavoro potrebbero essere eliminati nei prossimi decenni.
Bisogna però essere obiettivi e osservare che se alcuni tipi di lavoro sono destinati a scomparire, né più né meno di quanto avvenuto nelle precedenti rivoluzioni industriali e tecnologiche, al contempo ne emergono altri. La domanda di esperti in IA, sviluppatori di software, data scientist e altri professionisti tecnologici è infatti già in forte crescita, tutti ruoli che richiedono competenze avanzate, ponendo una sfida significativa per i lavoratori meno qualificati o che operano in settori tradizionali.
L’IA come alleato dei lavoratori
Nonostante le giustificabili preoccupazioni, l’IA non rappresenta dunque solo una minaccia, ma può anche essere un potente alleato per tutti i lavoratori. Le tecnologie di intelligenza artificiale possono infatti aumentare la produttività dei lavoratori, consentendo loro di concentrarsi su compiti più creativi e strategici, mentre le macchine si occupano delle attività ripetitive e monotone, migliorando dunque anche l’approccio stesso al lavoro.
Gli assistenti virtuali e gli strumenti di automazione possono, per esempio, gestire e-mail, programmare riunioni e analizzare dati, liberando tempo prezioso per i dipendenti, mentre in settori come la sanità, l’IA sta assistendo i medici nella diagnosi e nel trattamento dei pazienti, migliorando la precisione e accelerando i processi. Anche in un settore come quello dell’intrattenimento digitale, poi, l’intelligenza artificiale si è dimostrata importantissima per migliorare tante attività differenti, dalla gestione delle meccaniche di svaghi come il poker online fino alla protezione dei dati finanziari e personali degli utenti che trasferiscono periodicamente denaro da e verso il proprio conto di gioco aperto su una delle piattaforme specializzate.

Foto di Maximalfocus su Unsplash Formazione continua: la chiave per il futuro
Per quanto descritto, uno dei nodi cruciali per rendere l’IA un’alleata e non una nemica del lavoro umano sta tutto nella capacità di formare i professionisti del futuro, puntando su competenze sempre più evolute e complesse. I lavoratori non devono temere la tecnologia, ma inevitabilmente sono chiamati ad adattarsi ai cambiamenti del mercato, acquisendo nuove competenze e aggiornando quelle esistenti. Le aziende, dal canto loro, devono investire nella formazione dei propri dipendenti, creando programmi di upskilling e reskilling per prepararli alle sfide future.
La collaborazione tra aziende, istituzioni educative e governi sarà pertanto fondamentale per creare un ecosistema in cui l’IA e i lavoratori possano coesistere in modo armonioso. Promuovere l’educazione tecnologica e incentivare i corsi di formazione professionale sono passi essenziali per garantire che la forza lavoro sia pronta ad affrontare le sfide dell’IA.
L’intelligenza artificiale sta rapidamente trasformando il futuro del lavoro e ciò è sotto gli occhi di tutti, ma non si può guardare al cambiamento solo come a una possibile minaccia per l’uomo. Se è vero che da un lato, infatti, l’automazione potrebbe eliminare molti posti di lavoro, l’altra faccia della medaglia ci mostra già da oggi vantaggi per ciò che riguarda la creazione di nuovi ruoli e la possibilità di lavorare in modo più efficiente, con prospettive decisamente positive. La chiave del successo sarà, in altre parole, l’adattabilità: lavoratori, aziende e istituzioni devono infatti collaborare sin da subito per garantire che tutti possano beneficiare delle innovazioni tecnologiche.
-
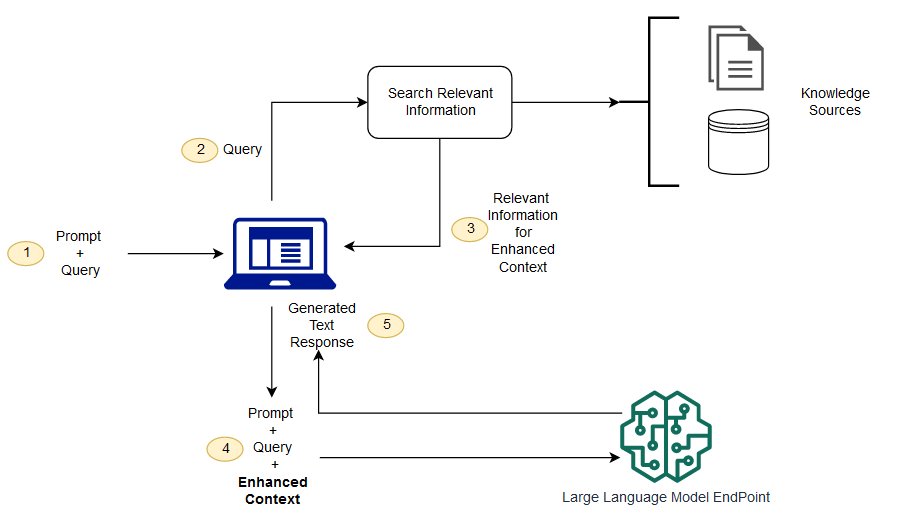
Che cos’è la rag AI
Credits: https://aws.amazon.com/it/what-is/retrieval-augmented-generation/ Il processo RAG si articola in diverse fasi:
- Creazione di dati esterni: Vengono raccolti e integrati dati da fonti esterne affidabili e pertinenti al contesto.
- Recupero di informazioni pertinenti: Quando viene posta una domanda all’IA, questa esegue una ricerca nelle fonti di conoscenza esterne per trovare informazioni rilevanti.
- Aumento del prompt LLM: Le informazioni recuperate vengono integrate nel contesto della domanda dell’utente, ampliando così l’input fornito al modello linguistico di base.
- Aggiornamento dei dati esterni: Per garantire la pertinenza e l’attualità delle informazioni, i dati esterni vengono aggiornati periodicamente in base alle nuove informazioni disponibili.
In sintesi, la Retrieval-Augmented Generation rappresenta una tappa significativa nell’avanzamento delle tecnologie linguistiche dell’IA, consentendo alle IA generative di fornire risposte più accurate, aggiornate e affidabili. Questo approccio offre vantaggi significativi in termini di implementazione, fiducia degli utenti e controllo degli sviluppatori, contribuendo così a sbloccare il pieno potenziale dell’intelligenza artificiale nel mondo reale.
-

Deep Nostalgia: il software che anima le foto
Lanciata dal portale MyHeritage un’innovativa (e forse anche un po’ inquietante) tecnologia in grado di produrre brevi filmati partendo da una foto.
Cosa ci può essere a metà strada tra una foto e un video? In fondo, la foto, per sua natura, cattura un momento statico, mentre il video un momento dinamico. Non esiste fisicamente un “terzo stato” in cui una figura possa essere immortalata. Ma il noto portale di ricerche genealogiche MyHeritage ha cercato di superare questo dualismo, inventando l’app chiamata DeepNostalgia.
Che cos’è DeepNostalgia
Il concetto alla base dell’applicazione è semplicissimo da spiegare: caricate una vostra foto, sia essa di pochi minuti fa o risalente a decenni or sono, e l’intelligenza artificiale che sta alla base del programma, in meno di mezzo minuto, sarà in grado di dare vita alla foto trasformandola in un breve filmato di alcuni secondi.
Visualizza questo post su InstagramNon solo: il portale garantisce che l’app funzioni efficacemente anche sui quadri – ovviamente non su tele tipo Guernica o L’Urlo ma, magari, sulla Gioconda il suo effetto apprezzabile lo potrà assicurare – e sul suo sito (a questo link https://www.myheritage.it/deep-nostalgia) sono stati pubblicati alcuni interessanti samples esplicativi.

Come funziona DeepNostalgia
Ovviamente, questa non è una tecnologia del tutto nuova. Dalla produzione del film Il Corvo in poi – quando, a causa della prematura morte sul set dell’attore protagonista, Brandon Lee, è stato necessario ricorrere ad un computer che “resuscitasse” il personaggio per poter completare le scene mancanti – la computer grafica ha fatto passi da gigante nella creazione di “avatar” digitali di attori defunti – ad esempio Peter Cushing, morto nel 1994, è stato “resuscitato” per interpretare la parte di Tarkin in Rogue One del 2016, spin-off di Guerre Stellari – o per ringiovanirne altri – sempre nel film Rogue One, compare un avatar che interpreta Carrie Fisher nei panni della giovane principessa Leia (la Fischer morirà a sessant’anni il 27 dicembre 2016, due settimane dopo la prima del film). Stessa cosa è stata fatta nel film Il Grande Match con Sylvester Stallone e Robert De Niro in cui, nelle scene iniziali, si vedono i due attori ringiovaniti digitalmente di decenni (a riportarli indietro nel tempo all’epoca dei loro film culto Rocky e Toro Scatenato) che danno vita ad un incontro di boxe.
Allo stesso tempo, negli ultimi anni, oltre ad app in grado di deformare, invecchiare, ringiovanire e trasformare in tutti i modi possibili i volti (e tramite queste app, sembra, gli sviluppatori abbiano ceduto i dati sensibili degli utenti a non ben precisati enti russi e cinesi, che ignoriamo cosa ne stiano facendo ora), diversi sono stati i casi di deepfake creati utilizzando dei software particolarmente avanzati per ricreare avatar dalle sembianze di personaggi famosi cui sono state fatte pronunciare frasi e discorsi che non ci si aspetterebbe mai di sentire uscire dalle “vere” bocche di costoro. In alcuni casi, addirittura, a numerose famose e bellissime attrici è capitato, loro malgrado, di ritrovarsi a “recitare” in film pornografici per via dell’immagine del loro viso ricostruito digitalmente su quello di attrici hard in carne e ossa.
Rispetto ai casi succitati, comunque, DeepNostalgia – vuoi anche per la serietà del portale che lo ha messo online, conosciuto da anni come un affidabile mezzo per ricostruire alberi genealogici – promette di avere un approccio più intimo e privato, non essendo possibile condividere le foto con terze parti (anche se, al riguardo, gli escamotage sembrano essere dietro l’angolo) come pure, per chiara scelta degli sviluppatori, non si potrà far abbinare alla fotografia una traccia audio, evitando così il verificarsi di abusi come avvenuto in tanti casi di deep fake.
Deepfake, deepfake ovunque
La tecnologia che sta alla base del programma non si discosta molto da quella usata in campo cinematografico e consiste di una intelligenza artificiale in grado di simulare il movimento dei muscoli del viso, dei capelli, delle ombre e di accessori e abiti indossati, impresso in foto. Alcuni dei samples pubblicati da MyHeritage sono sbalorditivi altri, invece, denotano un prodotto ancora migliorabile sotto tanti aspetti ma che comunque produce un risultato sempre abbastanza realistico. Ovviamente, al contrario delle attrezzature di cui necessitano le produzioni Hollywoodiane, per far funzionare DeepNostalgia basta un normale PC o un comune smartphone e, per questo, siamo sicuri che l’app avrà un immediato successo a cui, presto, seguiranno prodotti emuli nel creare i quali, temiamo, i programmatori porranno meno cura nel rispettare normative relative alla privacy e simili.
Il servizio messo a disposizione da MyHeritage consente di sviluppare un numero illimitato di fotografie per coloro che dispongono di un abbonamento completo al portale, ma sarà anche possibile “animare” gratuitamente un numero limitato di fotografie per i non abbonati. Le foto gratuite riporteranno una filigrana con il logo del sito che sarà assente in quelle degli abbonati.
Immagine di copertina: PocketBook
