Qual è la versione preferibile di PHP per il nostro sito?
In molti casi ci prendiamo la versione che viene fornita dall’hosting senza entrare nel merito, e ci sono circostanze in cui è preferibile che sia così. Ci sono casi, pero’, in cui la scelta della versione determina in modo deciso sia le prestazioni del sito che il funzionamento del CMS, per cui bisognerà fare attenzione a sceglierla con cura.
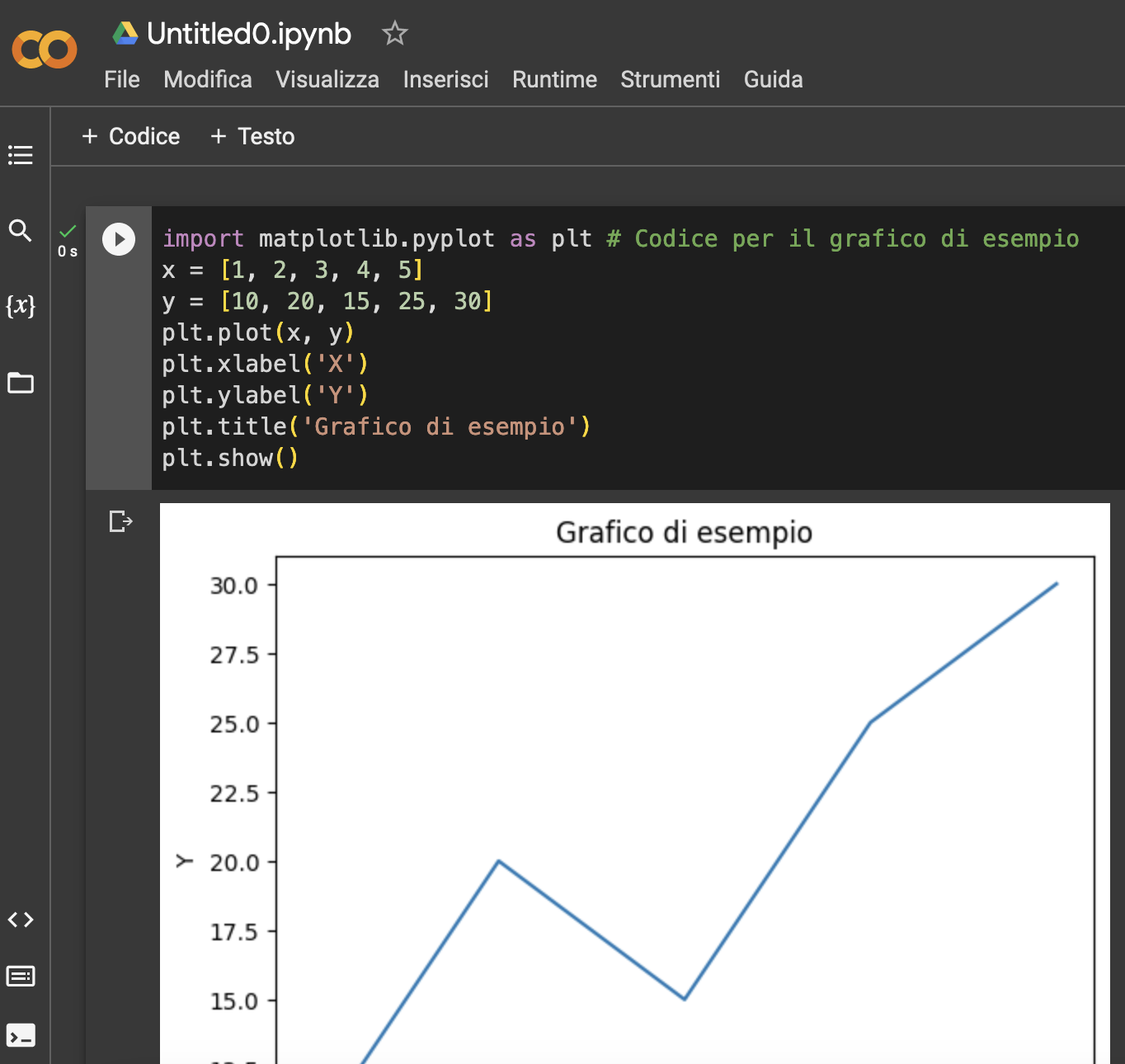
Capire PHP e le sue versioni diverse: 5, 7, 8.1 …
Cosa cambia tra le diverse versioni di PHP?
Ogni versione di PHP, in generale (e senza entrare in dettagli tecnici avanzati) supporta un insieme preciso di funzionalità : in genere più è recente la versione che usiamo, più sarà ampio e funzionale il set di funzioni disponibili. Tale disponibilità si pone anche nell’uso di particolari funzioni che richiedono per forza PHP, e di conseguenza la disponibilità di moduli, librerie avanzate e di complemento o ottimizzazione del sito saranno molto dipendenti da questa variabile.
Se diciamo PHP versione 8.1, ad esempio, 8 rappresenta la versione principale mentre 1 la sotto-versione specifica. A volte possono essere presenti due punti a separare le diverse versioni di PHP:
8.1.9 è l’ultima versione PHP disponibile al momento in cui aggiorniamo l’articolo, ad esempio.
Andare nel pannello di controllo dell’hosting
Nei pannelli di controllo dei principali servizi di hosting (cPanel, Plesk, ecc.), spesso viene riferito il numero principale di versione del linguaggio PHP in uso nel vostro sito, senza specificare la release (ad esempio PHP 5, e non PHP 5.6 o 5.7, la release è rispettivamente 6 e 7, mentre la versione è sempre 5); in genere, questo significa che l’utente dovrà accettare la scelta di default, che ha stabilito il sistemista in precedenza, oppure – se l’opzione è disponibile – potrà cambiarla mediante uno switch apposito che le ultime versioni di cPanel e Plesk offrono.
In genere, in caso di dubbi, conviene accettare la scelta della versione del linguaggio PHP senza cambiarla ,per evitare di complicarsi inutilmente la vita e perchè cambiando versione potremmo dare adito a malfunzionamenti o incompatibilità nel nostro sito.
Criterio migliore per la scelta di una versione PHP: scegliere l’ultima versione stable!
La realtà dei CMS e dei siti web reali è fatta di decine di casi intermedi, specialistici, adattati anche su una variabile che fin qui non abbiamo considerato ovvero il server ospitante; non è realistico pensare che tutti gli hosting supportino qualsiasi cosa, per cui dovremo sempre orientare la nostra scelta dell’hosting su un qualcosa che possa darci quello che ci serve per il CMS che intendiamo utilizzare. Un criterio generale che potete applicare per determinare la versione di PHP da installare è il seguente: in mancanza di altre informazioni specifiche, provate sempre ad installare l’ultima versione stable, cioè che viene fornita attivamente dall’hosting in questione mediante pannello di controllo oppure via terminale remoto.
Se si usano PHP, MySQL e Apache abbastanza recenti uniti ad un software aggiornato all’ultima versione, non ci dovrebbe essere alcun problema di uso ed il problema della scelta del linguaggio neanche dovrebbe porsi. In genere, poi, bisogna tenere conto che il passaggio ad esempio dal vecchio PHP 4 al 5 può creare qualche problema a qualche specifica libreria del vostro sito, così come il passaggio dalla 5 alla 7 potrebbe far apparire errori o warning (anche se nella mia esperienza recente questo è un caso raro e non succede quasi mai). Tenete conto, comunque, che la scelta del PHP 7 orienta il vostro sito ad una maggiore velocità , visto che è stato progettato con in mente un miglioramento delle prestazioni generali del sito del 50% in media.
Come cambiare la versione di PHP in esecuzione nel sito
Per scegliere la giusta versione di PHP, basta accertarsi dall’indirizzo
che sia una versione stable (stabile); al momento le versioni stabili più recenti sono:
8.1.9 (l’ultima disponibile)
7.4.4
7.3
7.2
7.1
7.0
5.6
5.5
Posso usare versioni più vecchie di PHP
Sì certo, anche se in genere non conviene usare le versioni più datate, perchè potrebbero contenere dei bug non risolvibili, esporvi a falle di sicurezza o non essere più supportate (cioè, in gergo, aver raggiunto l’End Of Life). Ad ogni modo alcuni siti non funzionano con le versioni nuove di PHP, quindi se volete lasciarli online dovrete per forza usare una versione supportata dal vostro CMS, anche se non è nuovissima.
Di norma, ma questo vale per qualsiasi software, non è neanche detto che l’ultima versione sia la migliore, perchè dipende dalle caratteristiche tecnica della versione in questione, e dipende anche e soprattutto dai requisiti imposti dal CMS.
Andiamo quindi a vedere cosa richiedono, attualmente, i più diffusi CMS per quello che riguarda PHP. In pratica cercheremo di dettagliare i requisiti di sistema dei vari CMS per poter far funzionare PHP, MySQL e Apache / NGINX nel modo migliore possibile, il tutto utilizzando un linguaggio semplice e chiaro anche per i meno esperti.
WordPress
Ad oggi WordPress richiede:
- PHP versione 7.2 o 8.1
- MySQL 5.6 o successive (in alternativa, MariaDB 10.0 o superiori)
- Supporto al protocollo HTTPS (anche con certificati gratuiti come Let’s Encrypt)
In genere è buona norma accertarsi che l’hosting presso cui andate supporti appieno tutte queste caratteristiche. Le vecchie versioni di WP continuano a funzionare con la 7.1 o con la 5.6, ma in genere è sconsigliabile continuare a farne uso per troppo tempo: conviene sempre aggiornare all’ultima versione.
Joomla!
Ad oggi Joomla! 3.x richiede:
- consigliato PHP versione PHP 7 (minimo PHP 5.3.10)
- MySQL 5.1 o successive (in alternativa, SQL Server minimo 10.50.1600.1 oppure PostGreSQL 8.3.18)
- Apache 2.0 o successive (oppure NGINX 1.0 oppure Microsoft IIS 1.0 minimo)
- Supporto al protocollo HTTPS (anche con certificati gratuiti come Let’s Encrypt)
Invece Joomla! 1.6, 1.7 e 2.5 richiedono:
- consigliato PHP versione 5.6 (almeno PHP 5.2.4)
- MySQL 5.0.4 o successive (in alternativa, SQL Server minimo 10.50.1600.1, PostGreSQL non supportato)
- Apache 2.2 o successive (oppure NGINX 1.0 oppure Microsoft IIS 1.0 minimo)
In genere è buona norma accertarsi che l’hosting presso cui andate supporti appieno le rispettive caratteristiche. Le vecchie versioni di Joomla! continuano a funzionare con versioni di PHP più vecchie, ma anche qui in genere non è buona norma farne uso.
Magento
Il supporto PHP a Magento non è banale da far capire, in quanto non esiste un supporto uniforme alle varie versioni, a differenza di quello che accade per altri CMS. Pero’ proveremo lo stesso a rendere divulgativa questa idea: del resto la complessità del sistema giustifica questo genere di comportamento bizzarro, ma che deve essere tenuto in conto molto bene dai webmaster per non incorrere in problemi nel seguito.
Attualmente Magento 2.1 richiede:
- Apache 2.2 oppure 2.4 (in alternativa NGINX 1.8)
- MySQL 5.6 (Se usate Magento 2.1.2 bisogna optare per MySQL 5.7)
- PHP 7.0.2, 7.0.4, 7.0.6, 7.0.x, 5.6.5–5.6.x (le altre versioni NON sono supportate)
Sono inoltre richieste le estensioni PHP seguenti, che devono essere fornite dall’hosting o installate da voi in ambiente dedicato o VPS:
- bc-math (se usate Magento Commerce)
- curl
- gd, ImageMagick 6.3.7 (o successive)
- intl
- mbstring
- mcrypt
- hash
- openssl
- PDO/MySQL
- SimpleXML
- soap
- xml
- xsl
- zip
- solo se usate PHP 7:
- json
- iconv
Per questioni di performance, è altamente consigliato fare uso di PHP OPcache ed assicurarsi che sia abilitato e funzionante.
Prestashop
Per questo famoso e potentissimo CMS per l’e-commerce è richiesto:
- Apache 1.3, Apache 2.x, Nginx oppure Microsoft IIS
- PHP almeno 5.4 o superiori
- MySQL 5.0
Photo by CalEvans